Intel's 65nm Processors: Overclocking Preview
by Anand Lal Shimpi on October 25, 2005 12:05 AM EST- Posted in
- CPUs
Power Consumption of Intel's 65nm Processors
Other than poor performance, extremely high power consumption has been a frequently voiced criticism about Intel's Prescott. Thanks to its 31+ stage pipeline and high clock speeds, the Pentium 4 and Pentium D tend to draw quite a bit of power. How does 65nm change the power consumption landscape?
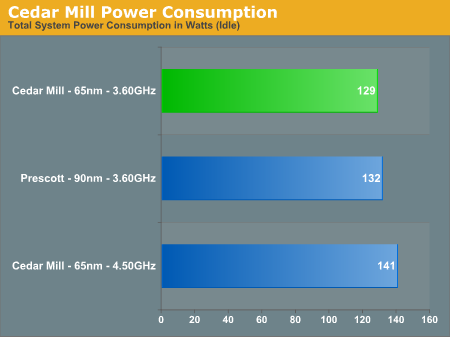
First up is Cedar Mill:
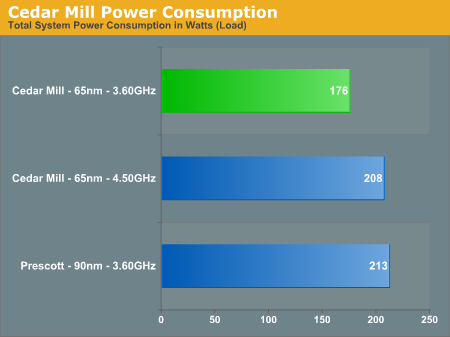
Next up, we loaded two threads of POV-ray's benchmark to fully load the CPUs and compare power consumption under load:
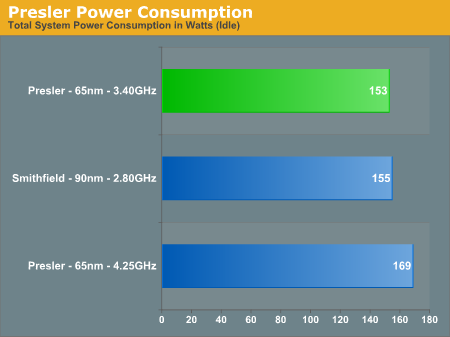
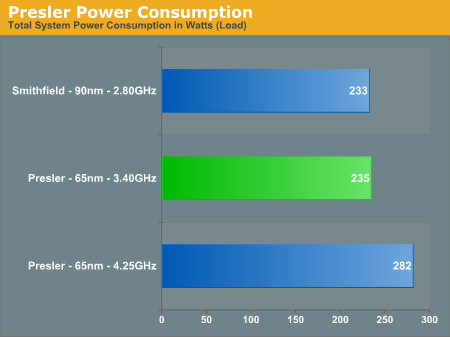
Next, we have Intel's dual core processors - Smithfield (90nm) and Presler (65nm):
Other than poor performance, extremely high power consumption has been a frequently voiced criticism about Intel's Prescott. Thanks to its 31+ stage pipeline and high clock speeds, the Pentium 4 and Pentium D tend to draw quite a bit of power. How does 65nm change the power consumption landscape?
First up is Cedar Mill:
Next up, we loaded two threads of POV-ray's benchmark to fully load the CPUs and compare power consumption under load:
Next, we have Intel's dual core processors - Smithfield (90nm) and Presler (65nm):








43 Comments
View All Comments
highlandsun - Tuesday, October 25, 2005 - link
Core-to-core is extremely important in a lot of multi-threaded applications. Remember that the programming model for threading is that multiple threads share one address space and so have shared access to data. Thread synchronization with mutexes and such requires that all processors have fast access to the mutex variables. As such, core-to-core communication is crucial.Viditor - Tuesday, October 25, 2005 - link
Thanks highland...some other questions if you could help.Do you have any idea as to how much bandwidth would increase for just the core to core traffic during multitasking?
What effect would increased latency for the core to core have on overall multitasking?
JarredWalton - Tuesday, October 25, 2005 - link
I should also mention that DC could actually be slower than 2P in cases where you have say 2 DIMMs per socket and a UMA-aware OS.Here's the real problem, Highland: in theory faster core-to-core speeds are important for SMP code. In reality, mutex and thread synchronization is bad. You don't want SMP software to spend a lot of time waiting to enter exclusive code blocks. In an ideal SMP application, you spend a fraction of time splitting up a task into two equal halves, then you let two cores churn away on those tasks for a relatively long time, and then you spend a fraction of time combining the results/synchronizing. If you're spending a lot of effort on thread synchronization, then you've got a task or algorithm that doesn't work very well for SMP in the first place.
This is more guesswork and supposition than actual knowledge. If someone has a concrete set of benchmarks that show real-world SMP doing much better (or worse!) on DC vs. 2P, I'd love to hear about it. If you can prove that the faster core-to-core speeds are what leads to better results in a real scenario, I'd like to hear about the application as well. Maybe I'm just not being creative enough, but I'm having a difficult time coming up with a task that's going to do great on SMP and also show a marked improvement on DC vs. 2P. The more independent the pieces of a task are, the better it will do on SMP setups, and conversely the less important core-to-core signaling becomes.
highlandsun - Tuesday, October 25, 2005 - link
Yes, "an ideal SMP application" may allow coarse grained division of labor. That may apply to supercomputing applications, where array/vector operations tend to dominate. That's a good model of SIMD computing, but that isn't the only model that users will run into.I think that class of problem is actually pretty rare. More often you need concurrent access to shared data. E.g., a web server with lots of front-end tasks talking to a multi-threaded database server. Since any number of threads may be writing new data while other threads are querying for data, all data accesses must be synchronized. For this class of problem, I expect the AMD design will have a noticable advantage.
This is significant, because I believe this class of problem is far more relevant in every day use. Think of the filesystem drivers in your OS, the databases behind big search engines like Google, etc., they're all about moderating multiple accessors to shared data. The faster your core-to-core communication, the better you can handle this type of task, and you run into this task every minute that you touch a computer.
JarredWalton - Wednesday, October 26, 2005 - link
There will be a few areas it helps, but I really don't think it will matter much. Most mutex accesses will be a very small fraction of the total compute time. Let's say that in a given second, you have 2 billion operations that a CPU can execute. How many of those will have to do with core-to-core work? If I were to take a stab at a figure, I'd wager that far less than 1% of instructions are going to do that:if(checkmutex()) {
do_massive_subroutine();
}
else {
wait();
}
Whatever the actual code is, the semiphore test condition and such are only a few machine instructions. The code that does the work might be thousands or tends of thousands of machine instructions. Basically, I think you'll end up with fine-grained threading benefiting a bit from the faster intercore bandwidth/latency, but it's not going to be an amazing improvement. A synthetic application to test just this "bottleneck" might be able to show a 25% improvement in intercore communication speed, but best case scenario I doubt it will end up being more than 2 to 5% faster in real code.
fitten - Tuesday, October 25, 2005 - link
Yes, the more coarse grained your application is, the better it will do. The more coarse grained your application is, the less synchronization and data sharing between the threads. Fine grained is more synchronization and sharing. The synchronization costs (mutexs and such) can be small compared to the amount of MOESI traffic required when two simultaneously running threads actually work on the same data, that's why you typically try to partition the data across threads so that they share as little as possible (when you can do this, it isn't always possible depending on the algorithms you are using). I've seen benchmarks that supposedly share a bit of data between threads and that's where the dual-cores (AMD) do well compared to the dual socket/single core Opterons because the dual-core MOESI traffic overhead is a bit less than going off-chip. I haven't really seen much from the Intel side of things, though, but I would expect that they wouldn't be too much different from dual-socket/single-core Xeons if their MOESI traffic has to go off chip.Viditor - Tuesday, October 25, 2005 - link
I'm not so sure...the intercore communication on the split cores goes from the cache of CPU0, through the FSB to the Northbridge, and then back to the cache of CPU1. That's what happens on Smithfield as well...
The AMD example won't be quite as severe (2P vs DC) because the the intercore comms go directly via the HT link on 2P...
How much traffic is sent is a very good question, and frankly I have no idea (anyone else have an answer to this?).
mino - Tuesday, October 25, 2005 - link
No, AMD DC's comunicate through CrossBar switch, not via HT link.Actually Smithfield was only a temporary measure, it is apparent Intel was able to design single die-multiple cores offering faster than multiple die-single package. Since the main reason for Smithfield is to have DC chips out ASAP, Intel has chosen the fastest route even if it meant it was more expensive. However with Presler Intel had enough time to perfect their Package&Chipset solutions to be able to accomodate 2 chips per package so the have chosen the more economical route this time.
I also believe the only single reason for 945/955 chipsets to exist was a premature release of PD. Now when Intel finally managed to make a chipset for Presler-like dualchip implementation, 945/955 are for no use except low-end offerings.
Anyway, IMHO Presler is much more dualchip solution the dualcore. Presler's SMP ability has almost nothing to do with the core itself. It is mostly the packaging& chipset issue exactly as with Xeon SMP implementation.
As of dualcore products are mostly from K8 family, Power5 family, Power 970 family, Yonah, most future Intel designs and to some extent Smithfield.
But Presler simply does not belong here.
Poetically said, Presler is product of the past while DC/MC is the future.
mrgq912 - Tuesday, October 25, 2005 - link
seems like there is lots of news from the intel front these days. People keep expecting intel to answer to amd's processor perfornmance effiency and power. But I don't here about any thing on the amd front. I am sure the gusy and amd are not sitting around waiting for intel to catch up, they must have something new in store besides a 1 more pin on a new socket.GlobalAmityPeter - Tuesday, October 25, 2005 - link
I have to agree with Lal Shimpi that Intel's imminent CPUs are less than exciting. Progress is always good, but aside from the novelty of overclocking to over 4GHz there isn't much of a draw with CedarMill and Presler. However until AMD manages to make public some plans for innovation beyond new sockets, I think Intel has a good chance at overtaking AMD in the performance realm with slow and steady progress.The competition between the two just isn't that hot right now. Hopefully things will get interesting when both copmanies release dual core mobile chips next year.
http://globalamity.net">GlobalAmity.net