nForce 500: nForce4 on Steroids?
by Gary Key & Wesley Fink on May 24, 2006 8:00 AM EST- Posted in
- CPUs
New Feature: DualNet
DualNet's suite of options actually brings a few enterprise type network technologies to the general desktop such as teaming, load balancing, and fail-over along with hardware based TCP/IP acceleration. Teaming will double the network link by combining the two integrated nForce5 Gigabit Ethernet ports into a single 2-Gigabit Ethernet connection. This brings the user improved link speeds while providing fail-over redundancy. TCP/IP acceleration reduces CPU utilization rates by offloading CPU-intensive packet processing tasks to hardware using a dedicated processor for accelerating traffic processing combined with optimized driver support.While all of this sounds impressive, the actual impact for the general computer user is minimal. On the other hand, a user setting up a game server/client for a LAN party or implementing a home gateway machine will find these options valuable. Overall, features like DualNet are better suited for the server and workstation market and we suspect these options are being provided since the NVIDIA professional workstation/server chipsets are typically based upon the same core logic.
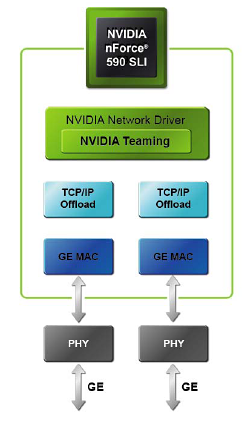
NVIDIA now integrates dual Gigabit Ethernet MACs using the same physical chip. This allows the two Gigabit Ethernet ports to be used individually or combined depending on the needs of the user. The previous NF4 boards offered the single Gigabit Ethernet MAC interface with motherboard suppliers having the option to add an additional Gigabit port via an external controller chip. This too often resulted in two different driver sets, with various controller chips residing on either the PCI Express or PCI bus with typically worse performance than well-implemented dual-PCIe Gigabit Ethernet.
New Feature: Teaming
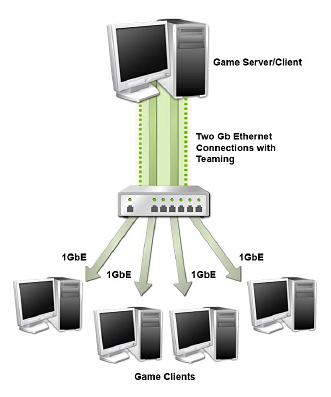
Teaming allows both of the Gigabit Ethernet ports in NVIDIA DualNet configurations to be used in parallel to set up a 2-Gigabit Ethernet backbone. Multiple computers can be connected simultaneously at full gigabit speeds while load balancing the resulting traffic. When Teaming is enabled, the gigabit links within the team maintain their own dedicated MAC address while the combined team shares a single IP address.
Transmit load balancing uses the destination (client) IP address to assign outbound traffic to a particular gigabit connection within a team. When data transmission is required, the network driver uses this assignment to determine which gigabit connection will act as the transmission medium. This ensures that all connections are balanced across all the gigabit links in the team. If at any point one of the links is not being utilized, the algorithm dynamically adjusts the connections to ensure optimal or formance. Receive load balancing uses a connection steering method to distribute inbound traffic between the two gigabit links in the team. When the gigabit ports are connected to different servers, the inbound traffic is distributed between the links in the team.
The integrated fail-over technology ensures that if one link goes down, traffic is instantly and automatically redirected to the remaining link. As an example, if a file is being downloaded, the download will continue without loss of packet or corruption of data. Once the lost link has been restored, the grouping is re-established and traffic begins to transmit on the restored link.
NVIDIA quotes on average a 40% performance improvement in throughput can be realized when using teaming, although this number can go higher. In a multi-client demonstration, NVIDIA was able to achieve a 70% improvement in throughput utilizing six client machines. In our own internal test we realized about a 45% improvement in throughput utilizing our video streaming benchmark while playing Serious Sam II across four client machines. For those without a Gigabit network, DualNet has the capability to team two 10/100 Fast Ethernet connections. Once again, this is a feature set that few desktop users will truly be able to exploit currently, but we commend NVIDIA for some forward thinking in this area.
Improved Feature: TCP/IP Acceleration
NVIDIA TCP/IP Acceleration is a networking solution that includes both a dedicated processor for accelerating networking traffic processing and optimized drivers. The current nForce500 MCPs have TCP/IP acceleration and hardware offload capability built in to both native Gigabit Ethernet Controllers. This typically will lower the CPU utilization rate when processing network data at gigabit speeds.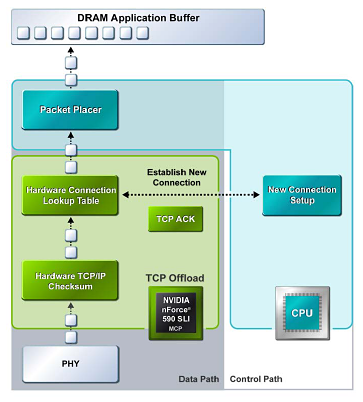
In software solutions, the CPU is responsible for processing all aspects of the TCP protocol: calculating checksums, ACK processing, and connection lookup. Depending upon network traffic and the types of data packets being transmitted, this can place a significant load upon the CPU. In the above example all packet data is processed and then checksummed inside the MCP instead of being moved to the CPU for software-based processing, and this improves overall throughout and reduces CPU utilization.
NVIDIA has dropped the ActiveArmor slogan for the nForce 500 release. The ActiveArmor firewall application has been jettisoned to deep space as NVIDIA pointed out that the features provided by ActiveArmor will be a part of the upcoming Microsoft Vista. No doubt NVIDIA was also influenced to drop ActiveArmor due to the reported data corruption issues with the nForce4 caused in part by overly aggressive CPU utilization settings, and quite possibly in part due to hardware "flaws" in the original nForce design.
We have not been able to replicate all of the reported data corruption errors with nForce4, but many of our readers reported errors with the nForce4 ActiveArmor even after the latest driver release. With nForce5 that is no longer a concern. This stability comes at a price though. If TCP/IP acceleration is enabled via the new control panel, then third party firewall applications (including Windows XP firewall) must be switched off in order to use the feature. We noticed CPU utilization rates near 14% with the TCP/IP offload engine enabled and rates above 30% without it.








64 Comments
View All Comments
Olaf van der Spek - Wednesday, May 24, 2006 - link
<quote>These devices can be configured in RAID 0, 1, 0+1, and 5 arrays. There is no support for RAID 10.</quote>That's probably because there's effectively no difference between 1+0 and 0+1 on a good controller.
Olaf van der Spek - Wednesday, May 24, 2006 - link
Doesn't this require support from the modem/router too?
The delay (usually) happens in the modem and not in the network card.
Zoomer - Saturday, May 27, 2006 - link
No, because you make the bottleneck your network card, instead of the modem. :)There will be a slight loss of throughput. Read some QoS articles. lartc.org is also a good resource. I bet it's the same principle. ;)
Trisped - Wednesday, May 24, 2006 - link
<quote>Multiple computers can to be connected simultaneously </quote>http://www.anandtech.com/cpuchipsets/showdoc.aspx?...">http://www.anandtech.com/cpuchipsets/showdoc.aspx?...
take out the "to"
Gary Key - Wednesday, May 24, 2006 - link
Thanks, it is corrected.....Googer - Wednesday, May 24, 2006 - link
When benchmarking core logic it's should be a high priority to measure I/O performance, since that is the primary job of any AMD Chipset.Where are the HDD, Network, Audio, and R.A.I.D. benchmarks?
Gary Key - Wednesday, May 24, 2006 - link
I answered above but we will have full benchmarks in the actual motherboard articles. Our efforts in the first three days was to prove out the platform and features that were added or changed (still doing it, feels weird to be up almost 72 hours). In answer to your question-
Foxconn Board
Network-
Throughput - 942 Gb/s
CPU utilization - 14.37% (with TCP/IP offload engine on), near 30% off.
HDD/RAID
No real difference compared to nF4 as we stated. The numbers are within 1% of each other. The interesting numbers will be in our ATI SB600 comparison.
Audio-
Dependent on the codec utilized in each motherboard, the RealTek ALC883 used in most of them have the same numbers as the nF4 boards. The only difference is the new 1.37 driver set we used. It will be interesting in the comparison as Asus went back to ADI for HDA.
Pirks - Wednesday, May 24, 2006 - link
That's why AT is my favorite review site - 'cause you're really crazy bunch :-) Just don't ruin yourself completely, we need you!Gary Key - Wednesday, May 24, 2006 - link
The ending should read NF4 Intel or ATI/Uli AMD boards. Where is that edit function? Hit enter too soon. :)Gary Key - Wednesday, May 24, 2006 - link
They will be in our roundup comparison and ATI AM2 articles.