A New SSE Instruction Set: AMD Announces SSE5
by Ryan Smith on August 30, 2007 4:00 PM EST- Posted in
- CPUs
So what's so important about being able to use 3+ operands? In a word: MADD, Multiply-ADDition operations (aka multiply-accumulate/MAC), such as C=(A*B)+C. Matrix math is the cornerstone of data processing and image rendering, and one of the cornerstone operations in manipulating a matrix is multiplying two elements and adding them to a third, which would require 3 operands. Modern GPUs are MADD powerhouses, with their stream processors capable of processing a mind-boggling number of such instructions in a short period of time; being fast at MADD is one of the specialized tasks that makes a GPU so fast at its job.
Meanwhile x86 processors have no real MADD abilities, so any time a CPU is doing the kind of image manipulation work that would benefit from MADD, instead it is executing separate multiply and addition instructions (and sometimes more). It should come as no surprise that AMD's favorite/most-publicized part of SSE5 then are instructions using 3+ operands since fusing two instructions in to one can theoretically double performance in certain situations. Furthermore using such instructions can cut down on the number of register load/store operations needed, which can save yet more time.
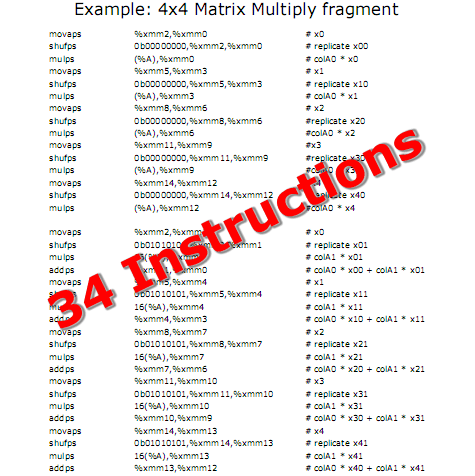
AMD has provided us with an example of such a situation, with the code for a 4x4 matrix multiplication operation, one coded optimally in SSE3, the other optimized via SSE5. The SSE3 code requires 34 instructions, meanwhile the SSE5 code does it in 20. Now there is more to the performance of such a code segment than the number of instructions (so this example isn't necessarily 41% faster) since the time to execute and retire an instruction can vary depending on the instruction, but it doesn't negate the performance improvement offered by such code.

For actual performance numbers with SSE5, AMD has told us that they've found that a discrete cosine transform - an operation important for image and movie encoding - can be done 30% faster using SSE5 than SSE3. They have even more impressive numbers for encryption processing, with a 5x performance improvement possible on certain encryption tasks, although we suspect this case is more limited than their image encoding scenario. Either way the promise of other performance improvements is there, however this is going to heavily depend on how well programmers will be able to extract additional performance out of SSE5, and how good AMD's own optimized math libraries will be once those are released.
This also isn't taking in to significant account instructions that are not part of the MADD/MAC set. All of AMD's examples today deal with improvements due to those instructions, meanwhile we don't have a lot of information on the performance aspects of the permutation, vector, or precision instructions. We have no doubt that they'll be similarly useful, we just don't know to what degree at this point.
Finally, as we're always watching how the predicted merging of CPUs and GPUs is progressing, this is a notable time. Although AMD is not targeting GPUs specifically with SSE5, as we mentioned before GPUs are particularly fast at MADD operations and meanwhile SSE5 is providing CPUs a shot in the arm in that area. This won't kill (or even significantly maim) the GPU, but it is one less thing that the GPU advantage is shrinking in. As SSE iterations keep coming out and implementing features similar to DSPs and GPUs, they will keep chipping away at their side of the barrier between the CPU and the GPU until very little is left and the two become one.








17 Comments
View All Comments
redpriest_ - Thursday, August 30, 2007 - link
SSE5 is far more robust than SSE4.ltcommanderdata - Thursday, August 30, 2007 - link
I was wondering whether there are any copyrights to the SSE and MMX names that Intel owns? SSE was originally started as a polarized opposition to 3DNow!, but I think having both Intel and AMD developing something dubbed "SSE" without a unified standard will get very convoluted very quickly. Like an SSE4a that appears to be a superset of SSE4 but is actually exclusive and SSE5 being only a partial superset. I can only imagine what would happen if Intel decided to label their next instruction set "the real SSE5" or introduce a SSE6 that completely skips over AMD's SSE5.You know, one of the things I've found interesting is how there are little things that Intel and AMD are doing can be viewed as appealing to Apple. Intel's Penryn for example has their Super Shuffle Engine which improves SSE packing, unpacking etc. which can be viewed as an attempt to meet the functionality of the Vector Permute Unit in the G4e and G5. Similarly, the move to 3-operand SSE also seems like an appeal to Altivec programmers.
MikeyJ79 - Thursday, August 30, 2007 - link
If I remember correctly, when AMD put MMX instructions in their K6 processor. Intel tried to sue them, but AMD won out. I don't remember the specific details, but I believe that was the jist of it.rcc - Thursday, August 30, 2007 - link
You don't horn in on other companys' naming schemes etc. It's actually more likely that someone seeing SSE5 will think it's an Intel spec than an AMD spec. I really dislike the whole lawsuit happy system we have going, but AMD needs to be slapped for this one.DigitalFreak - Thursday, August 30, 2007 - link
It's just AMD marketing BS, trying to make themselves look like they are leading again, like in the x64 days, instead of following. I wouldn't be surprised in the least if this ended up being called something else by the time it finally arrives.Omega215D - Friday, August 31, 2007 - link
Like AMD64 for Intel is called EM64T? Despite their competitive nature they still license tech from each other here and there.crimson117 - Thursday, August 30, 2007 - link
How does this benefit AMD?Does appearing to be (or becoming) a specification leader give them an advantage; for example is it easier for their chip designers to use AMD-developed specs than Intel-developed specs?
It seems like this cannot be a low-cost endeavor.