PCI Express 2.0: Scalable Interconnect Technology, TNG
by Kris Boughton on January 5, 2008 2:00 AM EST- Posted in
- CPUs
It should come as no surprise to anyone that the gaming industry is quite capable of forcefully driving the need for innovation - often found in the form of faster processors, more powerful 3D graphics adapters, and improvements in data exchange protocols. One such specification, PCI Express (PCI-E), was prompted for development when system engineers and integrators acknowledged that the interconnect demands of emerging video, communications, and computing platforms far exceeded the capabilities of traditional parallel buses, such as PCI. Although PCI Express is really nothing more than a general purpose, scalable I/O signaling interconnect, it has quickly become the platform of choice for industry segments that desperately need the high-performance, low latency, scalable bandwidth that it consistently provides. Graphics card makers have been using PCI Express technology for more than a generation now and today's choice of PCI Express-enabled devices is becoming larger by the minute.
Unlike older parallel bus technologies such as PCI, PCI Express adopts a point-to-point serial interface. This architecture provides dedicated host to client bandwidth, meaning each installed device no longer must contend for shared bus resources. This also removes a lot of the signal integrity issues such as reflections and excessive signal jitter associated with longer, multi-drop buses. Cleaner signals mean tighter timing tolerances, reduced latencies, and faster, more efficient data transfers. To the gamer, of course, only one thing really matters: more frames per second and better image quality. While PCI-E doesn't directly provide for that relative to AGP, it has enabled some improvements along with the return of multi-card graphics solutions like SLI and CrossFire. For these reasons, it is no wonder that PCI Express is the interconnect of choice on modern motherboards.
The typical Intel chipset solution provides a host of PCI Express resources. Connections to the Memory Controller Hub (MCH) are usually reserved for devices that need direct, unfettered, low-latency access to the main system memory while those that are much less sensitive to data transfer latency effects connect to the I/O Controller Hub (ICH). This approach ensures that the correct priority is given to those components that need it the most (usually graphics controllers). When it comes to Intel chipsets, a large portion of the market segment distinction comes from the type and quantity of these available connections. Later we will look at some of these differences and discuss some of the performance implications associated with each.
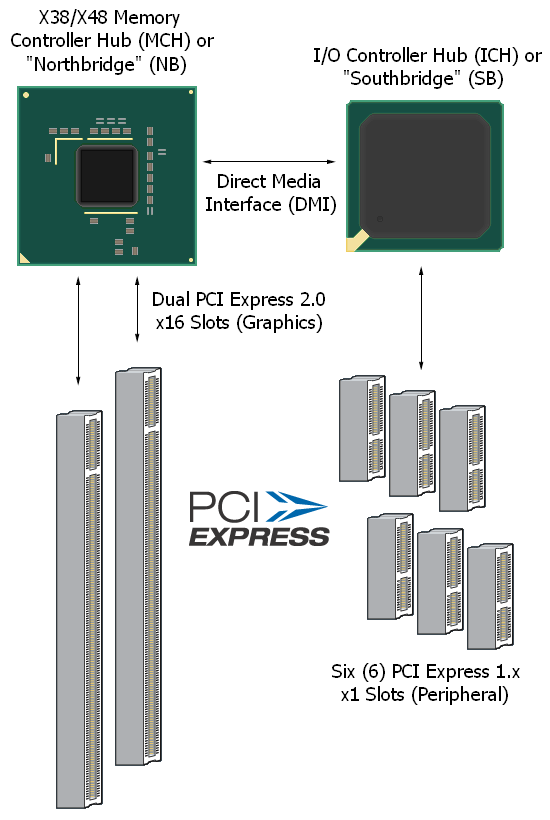
In late 2006, PCI-SIG (Special Interest Group) released the 2.0 update to the PCI Express Base Specification to members for review and comment. Along with the introduction of a host of new features comes the most predominant change of all, an increase in the signaling rate to 5.0GT/s (double that of the PCI Express 1.x specification of 2.5GT/s). This increase effectively doubles the maximum theoretical bandwidth of PCI Express and creates the additional data throughput capabilities that tomorrow's demanding systems will need for peak performance.
Both ATI/AMD and NVIDIA have released their first generation of PCI Express 2.0 capable video cards. ATI has the complete Radeon HD 3000 series while NVIDIA offers the new 8800 GT as well as a 512MB version of the 8800 GTS (G92) built using 65nm node technology. Last month we took an in-depth look at these new NVIDIA cards - our testing, comments, and conclusion can be found here. We reviewed the ATI models a little earlier in November - the results are interesting indeed, especially when compared to NVIDIA's newest offerings. Take a moment to review these cards if you have not already and then come read about PCI Express 2.0, what it offers, what has changed, and what it means to you.








21 Comments
View All Comments
rogerdpack - Monday, July 23, 2012 - link
So shouldn't the article list PCIe 2.0 throughput as 400 MB/s because of the 8b/10b encoding overhead?