The Nehalem Preview: Intel Does It Again
by Anand Lal Shimpi on June 5, 2008 12:05 AM EST- Posted in
- CPUs
Faster Unaligned Cache Accesses & 3D Rendering Performance
3dsmax r9
Our benchmark, as always, is the SPECapc 3dsmax 8 test but for the purpose of this article we only run the CPU rendering tests and not the GPU tests.
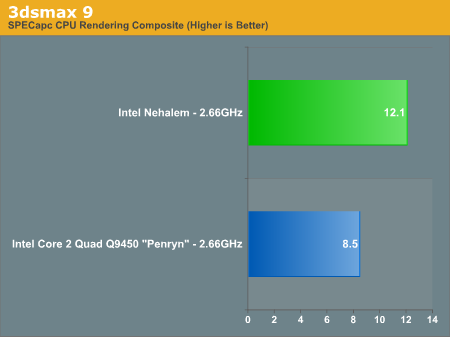
The results are reported as render times in seconds and the final CPU composite score is a weighted geometric mean of all of the test scores.
| CPU / 3dsmax Score Breakdown | Radiosity | Throne Shadowmap | CBALLS2 | SinglePipe2 | Underwater | SpaceFlyby | UnderwaterEscape |
| Nehalem (2.66GHz) | 12.891s | 11.193s | 5.729s | 20.771s | 24.112s | 30.66s | 27.357s |
| Penryn (2.66GHz) | 19.652s | 14.186s | 13.547s | 30.249s | 32.451s | 33.511s | 31.883s |
The CBALLS2 workload is where we see the biggest speedup with Nehalem, performance more than doubles. It turns out that CBALLS2 calls a function in the Microsoft C Runtime Library (msvcrt.dll) that can magnify the Core architecture's performance penalty when accessing data that is not aligned with cache line boundaries. Through some circuit tricks, Nehalem now has significantly lower latency unaligned cache accesses and thus we see a huge improvement in the CBALLS2 score here. The CBALLS2 workload is the only one within our SPECapc 3dsmax test that really stresses the unaligned cache access penalty of the current Core architecture, but there's a pretty strong performance improvement across the board in 3dsmax.
Nehalem is just over 40% faster than Penryn, clock for clock, in 3dsmax.
Cinebench R10
A benchmarking favorite, Cinebench R10 is designed to give us an indication of performance in the Cinema 4D rendering application.
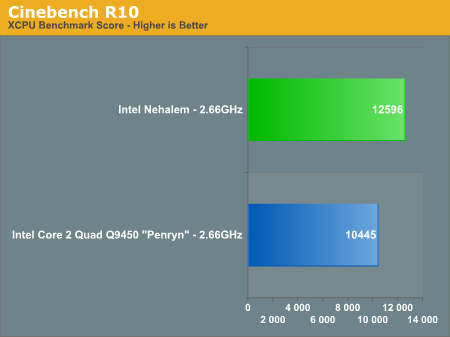
Cinebench also shows healthy gains with Nehalem, performance went up 20% clock for clock over Penryn.
We also ran the single-threaded Cinebench test to see how performance improved on an individual core basis vs. Penryn (Updated: The original single-threaded Penryn Cinebench numbers were incorrect, we've included the correct ones):
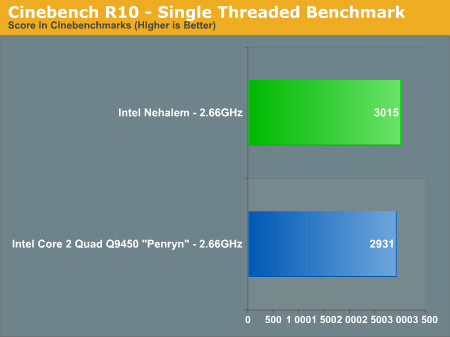
Cinebench shows us only a 2% increase in core-to-core performance from Penryn to Nehalem at the same clock speed. For applications that don't go out to main memory much and can stay confined to a single core, Nehalem behaves very much like Penryn. Remember that outside of the memory architecture and HT tweaks to the core, Nehalem's list of improvements are very specific (e.g. faster unaligned cache accesses).
The single thread to multiple thread scaling of Penryn vs. Nehalem is also interesting:
| Cinebench R10 | 1 Thread | N-Threads | Speedup |
| Nehalem (2.66GHz) | 3015 | 12596 | 4.18x |
| Core 2 Quad Q9450 - Penryn - (2.66GHz) | 2931 | 10445 | 3.56x |
The speedup confirms what you'd expect in such a well threaded FP test like Cinebench, Nehalem manages to scale better thanks to Hyper Threading. If Nehalem had the same 3.56x scaling factor that we saw with Penryn it would score a 10733, virtually inline with Penryn. It's Hyper Threading that puts Nehalem over the edge and accounts for the rest of the gain here.
While many 3D rendering and video encoding tests can take at least some advantage of more threads, what about applications that don't? One aspect of Nehalem's performance we're really not stressing much here is its IMC performance since most of these benchmarks ended up being more compute intensive. Where HT doesn't give it the edge, we can expect some pretty reasonable gains from Nehalem's IMC alone. The Nehalem we tested here is crippled in that respect thanks to a premature motherboard, but gains on the order of 20% in single or lightly threaded applications is a good expectation to have.
POV-Ray 3.7 Beta 24
POV-Ray is a popular raytracer, also available with a built in benchmark. We used the 3.7 beta which has SMP support and ran the built in multithreaded benchmark.
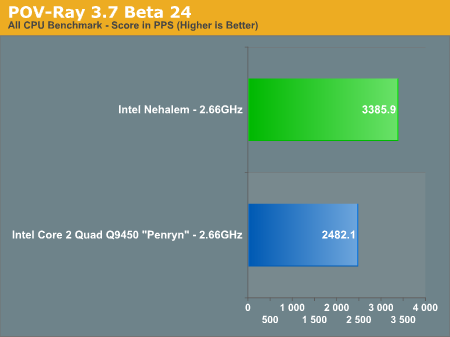
Finally POV-Ray echoes what we've seen elsewhere, with a 36% performance improvement over the 2.66GHz Core 2 Q9450. Note that Nehalem continues to be faster than even the fastest Penryns available today, despite the lower clock speed of this early sample.








108 Comments
View All Comments
ForumMaster - Thursday, June 5, 2008 - link
if you'd bother to read the article, it states quite clearly there are PCI-E issues which prevent any GPU testing as of now. it says the motherboard makers need another month to iron out the issues.what amazed me is how much better the performance is at this point. when nehalem is optimized, wow.
JPForums - Thursday, June 5, 2008 - link
I wouldn't expect much further optimization of the CPU. The only optimizations in code that couldn't have been made for Penryn would be further threading. Motherboard and chipset optimizations could make a difference, but only up to the point where they are mature. After that there will be little to differentiate CPU performance.Like with AMD, implementing the on-die memory controller gives Intel a free performance boost. There are no new instructions to implement and the improvement doesn't apply only to rare or obscure scenarios. Getting data into the core faster with less latency simply makes everything faster. It also serves to further minimize performance differences between supporting platforms.
What impresses me is that Intel got it right on the first try. It doesn't really surprise me as they have far more resources to work with, but it is nonetheless impressive.
The article mentions that Pat that said you can only add a memory controller once. Is this somehow different from any other architecture improvement? You can only add SSE or hyperthreading, or a new divider architecture once. Improvements to SSE2 and beyond or adding more thread support in hyperthreading are no different than putting in a DDR4 (or newer) controller with 4 (or more) channel support. Note: I don't advocate trying to add further thread support in hyperthreading. In fact, one of the few architectural change that I can think of that can be used more than once is increasing the cache size. Since AMD can't keep up with Intel's cache size due to process inferiority, it seems like an obvious viewpoint for Intel to take.
I suspect that the real reasons Intel didn't move over sooner were:
1) They didn't want to be seen as trailing AMD.
2) More importantly, an on-die memory controller reduces the advantage of larger caches. Alternately, from Intels perspective, a P4 processor would not have seen nearly as much benefit from an on-die memory controller due to its heavy reliance on large cache sizes. Benchmarks of the P4's showed that raw memory bandwidth was great for the P4s, but they couldn't care less about memory latencies (the largest advantage of an on-die memory controller) as they were hidden by the large cache size. Fast forward to the Core2's of today and you'll see major performance increases from lowering memory latencies on the X38/X48 chipsets. I believe this is true even to the point that the best performance isn't necessarily in line with the highest frequency overclock anymore. Even though Core2 has an even larger cache, it doesn't rely on it as much. Consider how much closer the performances of Intel's budget line (read: low cache) processors are to the mainstream than they were in the P4 era.
Intel was not going to introduce an on-die memory controller on an architecture that it made little sense to add it to. While it made sense with Core2, it would've taken much longer to get the chips out with one and Intel didn't have the luxury of time at Conroe's launch. Further, Intel would need to give something up to put it in. It is debatable whether they would see the same performance improvements depending on what got left out or changed. In conclusion, Intel added the on-die memory controller when it made the most sense.
Hyper-transport, on the other hand, was something Intel could've used a long time ago. Though they probably left it out because they weren't getting rid of the front side bus and they didn't want even more communications paths. Quickpath is a welcome improvement, though I'd really like to delve into the details before comparing it to hyper-transport. It'll be a real shame if they use time-division-multiplexing for the switching structure. (Assuming it supports multiple paths of course.)
The article mentions that the cache latencies and memory latencies are superior to Phenom's. While this is true, I don't really think AMD screwed anything up. Rather, Intel is simply enjoying the benefits of its smaller process technology and newer memory standard. You need look no further than Anandtech to find articles explaining the absolute latencies differences between DDR2 and DDR3. Intel memory latencies may still be a bit lower than AMD when they move over to the smaller process with a DDR3 controller, but I doubt it'll be earth shattering.
The good news for AMD is that Intel has essentially told them that they are on the right path with their architecture design. The bad news is that Intel also just told them that it doesn't matter if they are right, Intel is so fast that they can take a major detour and still find their way to the destination before AMD arrives. Hopefully, AMD will pick up speed once they're done paying for the ATI merger.
Gary Key - Thursday, June 5, 2008 - link
I was able to view but not personally benchmark a recently optimized Bloomfield/X58 system this week and it was blindingly fast in several video benchmarks compared to a QX9650. These numbers were before the GPUs became a bottleneck. ;)BansheeX - Thursday, June 5, 2008 - link
The performance conclusion might be a good example of why a monopoly is neither self-perpetuating or an inherently bad thing for the consumer. It IS possible for a virtual monopoly like Intel to be making the best product for the consumer. Perhaps the fear itself of losing that position is enough for such companies to not be complacent or attempt to overprice products, as it would open a window for smaller capital to come in and take marketshare. Just keep them away from subsidies and other special privileges, and the market will always work out for the best. You listening, Europe?Chesterh - Saturday, August 9, 2008 - link
Go back and to school and take Economics 101. Monopolies and corporate consolidation are part of the reason our economy is in the crapper right now. If the US government had been actually enforcing the antitrust regulations on the books, we might have done the same thing as Europe and slapped Microsoft on the wrist as well.Besides, Intel does not have a 'virtual monopoly', or any kind of monopoly. AMD is not out of the game; they are down in the high end CPU segment, but they are definitely not out. The only reason Intel is still releasing aggressively competitive new products is because it doesn't want to lose its lead over AMD. If there was no AMD, we might not even have multicore procs at this point.
SiliconDoc - Monday, July 28, 2008 - link
Uhhh, are you as enamored with Intel as Anand has been for as many years ?Did you say "monopoly not overprice it's products" ?
Ummm... so like after they went insane locking their multipliers because they hate we overclockers ( they can whine about chip remarkers - whatever) - they suddenly... when they could make an INSANE markup...ooooh..... they UNLOCKED their processor they "locked up on us".... made a "cool tard" marketing name and skyerocketed the price...
Well - you know what you said... like I wish some hot 21yr. old virgin would kiss me that hard.
With friends like you monopolies can beat all enemies... ( not that there's anything wrong with that).
\Grrrrr -
I know, you're just being positive something I'm not very good at.
I lost my cool when I read " the 1633 pin socket will be a knocked down 1066 version "for the public" or the like....
You never get the feeling your 3rd phalanx is permanently locked to your talus, both sides ?
Hmmm.... man we're in trouble.
Grantman - Sunday, July 6, 2008 - link
A monopoly is the worst thing that could happen for consumers in every regard, and the ease of entry for the smaller businesses to enter the processor market and gobble up marketshare is laughable. Firstly once a monopoly is established the can set the prices at any height they want and you think smaller players can take advantage of the opportunity and enter the sophisticated cpu market without being crushed by aggressive price cutting? Not only that, but as the monopoly makes it's close to 100% market share revenue it will reach a point were it's research and development is simply far ahead of any hopeful to enter the market thus perpetuating it's ongoing domination.Justin Case - Sunday, June 8, 2008 - link
The only reason why Intel came out with these CPUs at all is that there _is_ competition. Without that, Intel would still be run by its marketing department and we'd be paying $1000 for yet another 100 MHz increase on some Pentium 4 derivative.The words "a mononopoly isn't a bad thing for consumers" sound straight out of the good ol' USSR. You need to study some Economics 101; you clearly don't understand what "barriers to entry" or "antitrust" mean.
mikkel - Sunday, August 10, 2008 - link
Are you honestly suggesting that desktop performance requirements is the only thing driving processing innovation? I'm fairly sure that you'd find a very good number of server vendors whose customers wouldn't be satisfied with P4 derivatives today.There are market forces that Intel couldn't hold back even if they wanted to.
adiposity - Friday, June 6, 2008 - link
AMD is not dead yet and is still undercutting Intel at every price point they are able to. Intel will not rest until AMD is dead or completely non-competetive. At that point we may see a return to the arrogant, bloated Intel of old.All that said, their engineers are awesome and deserve credit for delivering again and again since Intel decided to compete seriously. They have done a great job and provided superior performance.
The only question is: will Intel corporate stop funding R&D and just rake in profits once AMD is dead and gone? I unless they get lucky in court in 2010, I think AMD's death is now a foregone conclusion.
Dan