Intel's Larrabee Architecture Disclosure: A Calculated First Move
by Anand Lal Shimpi & Derek Wilson on August 4, 2008 12:00 AM EST- Posted in
- GPUs
Drilling Deeper and Making the AMD/NVIDIA Comparison
Don't be fooled by the initial diagram, this simple x86 core gets far more complex. In the image below, the block to the left is the Larrabee core we mentioned earlier, to the right we've blown up the vector unit and its associated parts:
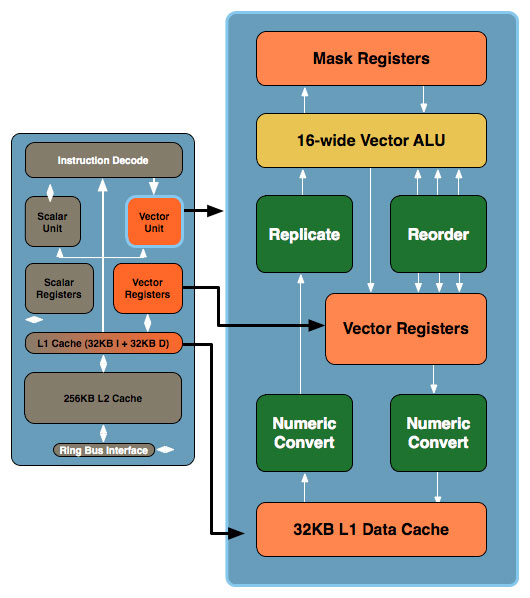
The vector unit is key and within that unit you've got a ton of registers and a very wide vector ALU, which leads us to the fundamental building block of Larrabee. NVIDIA's GT200 is built out of Streaming Processors, AMD's RV770 out of Stream Processing Units and Larrabee's performance comes from these 16-wide vector ALUs:
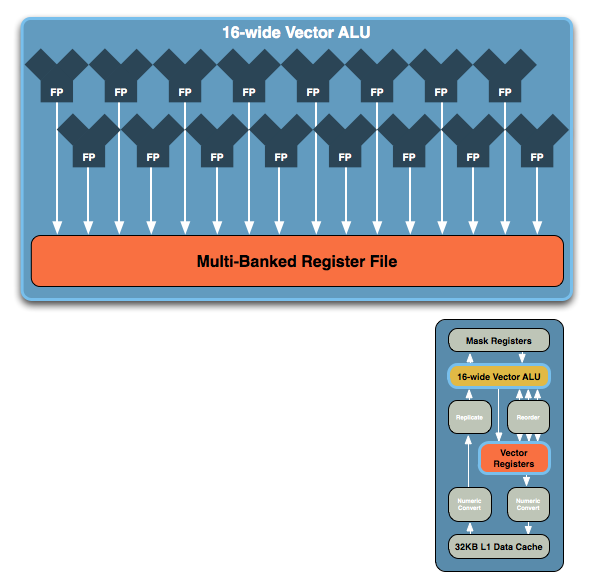
The vector ALU can behave as a 16-wide single precision ALU or an 8-wide double precision, although that doesn't necessarily translate into equivalent throughput (which Intel would not at this point clarify). Compared to ATI and NVIDIA, here's how Larrabee looks at a basic execution unit level:
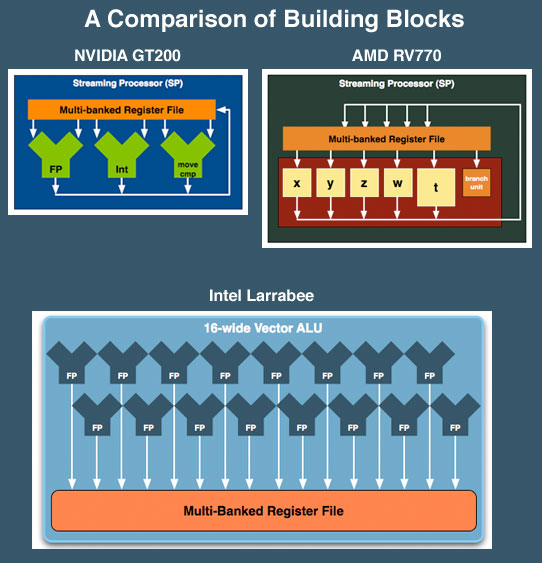
NVIDIA's SPs work on a single operation, AMD's can work on five, and Larrabee's vector unit can work on sixteen. NVIDIA has a couple hundred of these SPs in its high end GPUs, AMD has 160 and Intel is expected to have anywhere from 16 - 32 of these cores in Larrabee. If NVIDIA is on the tons-of-simple-hardware end of the spectrum, Intel is on the exact opposite end of the scale.
We've already shown that AMD's architecture requires a lot of help from the compiler to properly schedule and maximize the utilization of its execution resources within one of its 5-wide SPs, with Larrabee the importance of the compiler is tremendous. Luckily for Larrabee, some of the best (if not the best) compilers are made by Intel. If anyone could get away with this sort of an architecture, it's Intel.
At the same time, while we don't have a full understanding of the details yet, we get the idea that Larrabee's vector unit is sort of a chameleon. From the information we have, these vector units could exectue atomic 16-wide ops for a single thread of a running program and can handle register swizzling across all 16 exectution units. This implies something very AMD like and wide. But it also looks like each of the 16 vector execution units, using the mask registers can branch independently (looking very much more like NVIDIA's solution).
We've already seen how AMD and NVIDIA architectural differences show distinct advantages and disadvantages against eachother in different games. If Intel is able to adapt the way the vector unit is used to suit specific situations, they could have something huge on their hands. Again, we don't have enough detail to tell what's going to happen, but things do look very interesting.








101 Comments
View All Comments
DerekWilson - Monday, August 4, 2008 - link
this is a pretty good observation ...but no matter how much potential it has, performance in games is going to be the thing that actually makes or breaks it. it's of no use to anyone if no one buys it. and no one is going to buy it because of potential -- it's all about whether or not they can deliver on game performance.
Griswold - Monday, August 4, 2008 - link
Well, it seems you dont get it either.helms - Monday, August 4, 2008 - link
I decided to check out the development of this game I heard about ages ago that seemed pretty unique not only the game but the game engine for it. Going to the website it seems Intel acquired them at the end of February.http://www.projectoffset.com/news.php">http://www.projectoffset.com/news.php
http://www.projectoffset.com/technology.php">http://www.projectoffset.com/technology.php
I wonder how significant this is.
iwodo - Monday, August 4, 2008 - link
I forgot to ask, how will the Software Render works out on Mac? Since all Direct X code are run to Software renderer doesn't that fundamentally mean most of the current Windows based games could be run on Mac with little work?MamiyaOtaru - Monday, August 4, 2008 - link
Not really. Larrabee will be translating directx to its software renderer. But unless Microsoft ports the directX API to OSX, there will be nothing for Larrabee to translate.Aethelwolf - Monday, August 4, 2008 - link
I wonder if game devs can write their games in directx then have the software renderer convert it into larrabee's ISA on windows platform, capturing the binary somehow. Distribute the directx on windows and the software ISA for mac. No need for two separate code paths.iwodo - Monday, August 4, 2008 - link
If anyone can just point out the assumption anand make are false? Then it would be great, because what he is saying is simply too good to be true.One point to mention the 4Mb Cache takes up nearly 50% of the die size. So if intel could rely more on bandwidth and saving on cache they could put in a few more core.
And am i the only one who think 2010 is far away from Introduction. I think 2009 summer seems like a much better time. Then they will have another 6 - 8 months before they move on to 32nm with higher clock speed.
And for the Game developers, with the cash intel have, 10 Million for every high profile studio like Blizzard, 50 Million to EA to optimize for Intel. It would only cost them 100 million of pocket money.
ZootyGray - Monday, August 4, 2008 - link
I was thinking of all the p90's I threw away - could have made a cpu sandwich, with a lil peanut software butter, and had this tower of babel thing sticking out the side of the case with a fan on top, called lazarus, or something - such an opportunity to utilize all that old tek - such imagery.griswold u r funny :)
Griswold - Monday, August 4, 2008 - link
You definitely are confused. Time for a nap.paydirt - Monday, August 4, 2008 - link
STFU Griswald. It's not helpful for you to grade every comment. Grade the article if you like... Anandtech, is it possible to add an ignore user function for the comments?