Lucid's Multi-GPU Wonder: More Information on the Hydra 100
by Derek Wilson on August 22, 2008 4:00 PM EST- Posted in
- GPUs
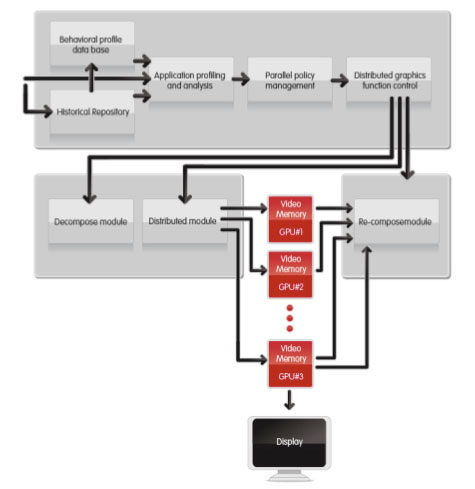
What Does This Thing Actually Do?From a high level, Lucid's technology intercepts DirectX or OpenGL API calls, analyzes them, organizes them into distinct tasks, and based on the analysis combined with the historical performance of various cards handling of previous frames' workload, it evenly distributes the tasks across all the GPUs in the system.
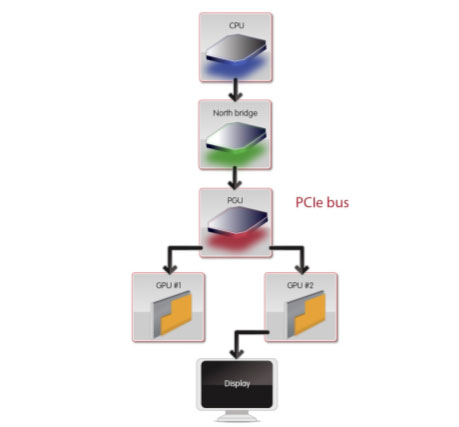
After the workload is distributed, the buffers are read back to the Hydra chip and composited before the final scene is sent to the proper graphics card for display. Looking a bit deeper, here is a block diagram of the process itself from Lucid's whitepaper.
The current implementation can take x16 PCIe in and can switch it to either 2x x16 PCIe channels or up to 4x x16 PCIe channels. This gives it support for 1 to 4 cards depending on how the motherboard or graphics card handles things. They do have the flexibility to scale down to x8 in and 2x x8 out, making lower cost motherboards feasible as well. Future products may support more graphics cards and more PCIe lanes, but right now 4 is what makes sense. Lucid says the hardware can scale up to any number of cards with linear performance improvement.
Some of the implications of this process are that if any graphics card in the system has other work being done on it (say maybe physics or video or something), the load will be dynamically balanced and you'll still be able to squeeze as much juice out of all the hardware in your system as possible. Pretty cool huh? If it works as advertised that is.
The demo we saw behind closed doors with Lucid did show a video playing on one 9800 GT while the combination of it and one other 9800 GT worked together to run Crysis DX9 with the highest possible settings at 40-60 fps (in game) with a resolution of 1920x1200. Since I've not tested Crysis DX9 mode on 9800 GT I have no idea how good this is, but it at least sounds nice.
Since Lucid is analyzing the data, they can even do things like not draw hidden "tasks" (if an entire object is occluded, rather than send it to a graphics card, it just doesn't send it down). I asked about dependent texturing and shader modification of depth, and apparently they also build something like a dependency graph and if something modified affects something else they are able to adjust that on the fly as well.
In theory, tracking and adjusting to dependencies on the fly will completely avoid the issues that keep NVIDIA and AMD from running AFR in all games. And they even claim that this can help give you higher than linear scaling when using their hardware with more than one card.
We asked what the latency of their implementation is, and they said it is negligible. Of course, that's not a real answer, especially for guys like us who want to know the details so we can understand what's going on better. We don't just want to see the end result, we want to know how we get there. Playing Crysis didn't feel laggy, but there is no way this solution doesn't introduce processing time.
An explanation for this is the fact that the Hydra software can keep requesting and queuing up tasks beyond what graphics cards could do, so that the CPU is able to keep going and send more graphics API calls than it would normally. This seems like it would introduce more lag to us, but they assured us that the opposite is true. If the Hydra engine speeds things up over all, that's great. But it certainly takes some time to do its processing and we'd love to know what it is.








57 Comments
View All Comments
haplo602 - Sunday, August 24, 2008 - link
The more I am reading about this Hydra thing, the more I believe it will turn out to be a hoax. Look at the thing in a logical way.1. we want to achieve multi-gpu scaling as best as possible
2. we cannot manipulate the scene data, since we don't know what the scene rendered actualy is (we can't identify object in a reasonable way)
3. the existing cards are already fast enough in actualy renderingthe scene
This boils down to an engine that offloads the actual scene set-up. If you look at the current SLI/CF mechanics, they either work in AFR mode or in split render mode. ATI/NVIDIA know enough about graphics to get to the same ideas Lucid did. However they abandoned the approach for some reason. That reason is consistency.
You cannot pick objects from a scene in any reliable way. Of course there are ways to separate objects. After all the programmer will usualy send one stream of rendering commands for one object etc. But that is not the rule.
You cannot do scene set-up on separate objects (things like removing not visible objects or parts of them) unless you are using some kind of z-buffer manipulation at the end.
I know very little about shader programs to tell how they work, but they also seem like a major issue in splitting a scene.
ATI/NVIDIA approach is the only reasonable one, and the only reason why they don't scale linarly is the scene set-up step. Each card has to do the same scene set-up every frame, thus this is the one thing that cannot be paralelised in a reasonable way and is lowering the gain in performance.
If Lucid found a way to do a scene set-up only once and split it to relevant parts for each card, they will have grave issues with optimised rendering paths for different DX/OGL/card versions. At one time, they will exhibit the same issues current CF/SLI does.
ATI/NVIDIA can simply implement this in software by making a GPU hypervisor engine.
Clauzii - Sunday, August 24, 2008 - link
Good post! Thumbs up :)pool1892 - Sunday, August 24, 2008 - link
ya, to me it is sort of the other way round - and still i agree. i am not sure what to expect, this is a technique i could imagine working.but it seems to be a job for a much stronger hardware - there is pattern recognition, on the fly optimization and balancing (different games will cleary be limited by different stages of the hardware rendering pipeline), qos (no latencies and sync) and many other things.
i have a hard time believing that this little programmable chip can do that amount of work without utilizing the cpu and without a local memory besides 16+16k L1, while it has to handle massive throughput.
so either they have found a REALLY clever trick or amd and nvidia could do the same, from a much better position, being in control of the complete environment. and well: why haven't they?
LOPOPO - Sunday, August 24, 2008 - link
If this thing works at it claims...... I would not be surprised. We know the problem with SLI/CS. Management pure and simple. The fact that we are all so astounded by this box speaks volumes to how much we are used to being screwed by Nvidia and ATI/AMD. It is obvious that Hydra allocates system resources far better that current solutions. The fact that it can do this and draw 5w (supposedly) just goes to show you how flawed SLI/CS really are.This seemingly, impending paradigm shift is occurring because card makers have a one track mind -bigger is better-. Add more memory...add more speed...more stream processors throw in ridiculous names then that equals success, bu not really. For them(AMD/Nvidia) yes, for you...somewhat... depending on how you shop. Nowadays performance demands are higher than ever and AMD/Nvidia solutions always = more power draw which creates more heat which must be dissipated which of course necessitates a larger profile card and cooler. Extremely inefficient.
It appears as if these newcomers are not trying to fit a square peg in a round hole. Can or could established card makers do this or something like this solution? Of course. But why when the consumer is perfectly happy spending ridiculous amounts of money for an extra 10 fps...AMD/Nvidia keep costs down and maximize profit it's all good for them. Consumers on the other hand rarely see the big picture. Such is the way this sector of the economy works, faster, more memory, die shrinks... never smarter, leaner, more efficient and the ever elusive: dynamic software/hardware architecture that adjust to given tasks. Those are my two cents and all of the above is contingent on the validity of Lucid's claims. I hope they are more valid than Nvidia's claims of 60% scaling in Crysis.
jeff4321 - Saturday, August 23, 2008 - link
C'mon, how can they perform better than AMD's Crossfire or NVIDIA's SLI? Teams at AMD and NVIDIA know the intimate details of their boards. They know what they're doing.Besides, someone could implement this kind of solution w/o hardware (the hardware is probably there to prevent folks from running the software w/o the Company getting revenue). Most likely what this hardware and software is doing is that their API interception code is directing all of the underlying cards to render parts of the frame to a surface on the framebuffer. The framebuffer is transferred to system memory. And then, depending on how you want to do things, you composite in system memory, or you direct the video card that is driving the video buffer to treat the system memory surface as an overlay surface.
All of this doesn't require magic hardware (unless you want to go really fast). This is how SLI and Crossfire work. Since AMD and NVIDIA designed their hardware and software, they can add hardware acceleration magic (things like synchronizing the two boards' scanout, directly transferring scanout data through the sli or crossfire cable, or making groups of boards look like one). Unfortunately for Lucid, I doubt that AMD or NVIDIA gave them any secret sauce so Lucid cannot leverage the hardware acceleration.
Their ASIC is just a PCIe switch with an endpoint device for software security.
whatthehey - Saturday, August 23, 2008 - link
I'm glad you're so incredibly knowledgeable that you can say what something does and how it works without ever seeing it or working on the project. Obviously nVidia and ATI don't want to give away their secrets, just like Lucid isn't going to give away theirs. Will this work? We don't know for sure yet. Is it better than SLI and Crossfire? We don't know that either. What I do know for certain is that there are plenty of games that are GPU limited that still don't get better than 30 to 50% scaling with current SLI/Crossfire. More than that, I know that most games don't come anywhere near even 50% scaling when going from dual GPUs to quad GPUs.I think the whole point of this chip is to do the compositing and splitting up of rendering tasks "really fast". I also think that the current ATI and nVidia solutions are less than ideal, given we need custom profiles for every game in order to see any benefit. What I'm most worried about is that the Lucid chip will just transfer the need for custom profiles from nVidia and ATI over to Lucid - a completely unproven company at this point.
For now, I'm interested in seeing concrete numbers and independent testing. The world is full of successful inventions that were deemed impossible or "smoke and mirrors" by dullards that just couldn't think outside the box. This Hydra chip may turn out to be exactly what you state, but I'm more inclined to wait and see rather than trusting on people like you to tell us what can and can't be done.
shin0bi272 - Saturday, August 23, 2008 - link
Im with Whatthehey. You are lucky to get 40 or 50% performance boost with current multi-gpu solutions and IIRC the game has to support either crossfire or sli. So if you are running say UT3 and have crossfire you are SOL for getting ANY boost if you are using AMD's crossfire. BUUUUT if the hydra tech works as advertised (or even close to it) it will be night and day to current solutions.If this chip is even exclusive to intel's mobos it will outperform either solution from amd/nvidia since it isnt alternating screens or portions of the screen via hardware over a tiny bridge (which adds latency). This chip is sort of like the hardware Xor chip on a raid5 card in that it just makes a decision on what card to send data to. The hydra's ONLY job is to intercept a data command being sent to the graphics card(s) and send it to the one that's not working as hard or is ready for a new operation. That doesnt take a lot of power or time as long as the software is efficient in telling the chip what graphics card(s) you have.
I read another comment that said: "the hydra is a tensilica diamond based programmable risc controller with custom logic around it running at 225mhz. it uses about 5watt."
For an explanation of RISC vs CISC visit: http://cse.stanford.edu/class/sophomore-college/pr...">http://cse.stanford.edu/class/sophomore-college/pr...
This chip does essentially 1 thing and does it very very very fast.
pool1892 - Sunday, August 24, 2008 - link
i made the tensilica 5watt risc chip comment - and the thing that is most interesting to me is that it is programmable to an extend. it is maybe best to imagine a dsp with a multitude of presets, each of which accelerates a different load. if i understand it correctly, hydra will autooptimize itself to suit different applications. this way you get near dsp throughput for many different usage models (that is different games) and you do not need the spezial units big fpga chips have.i just wonder where this optimization takes place, since hydra only has 16+16k of memory - and liquid talks about very low cpu utilization. (we are talking about a basic KI engine or really large table lookups)
risc v cisc is no business here, there are no real cisc chips left in the market (macro/micro ops and so on - this is gone since pentiumpro and the "weird shift from alpha to athlon"TM^^)
jeff4321 - Saturday, August 23, 2008 - link
If it is strictly software solution (where they call into DX for the multiple boards and eventually the rendered data makes it into system memory and the master board outputs the frame from system memory), of course it will work. Will it be fast and responsive? I don't know. If it is, you will see the same improvement in SLI or Crossfire because NVIDIA or ATI will figure out how the Lucid software is configuring their device. If you look at the block diagrams in the article, Lucid uses application profiles to determine how to configure the devices.A good comparison to Lucid's system is ATI's Software Crossfire (the Crossfire solution after the master-slave boards, but before Crossfire X cable like NVIDIA's SLI). Since ATI no longer runs this way, the Crossfire X solution is probably better. I doubt that ATI would stop using the software approach to multi-GPU solutions unless there were a benefit; the Crossfire X port makes the silicon bigger and it makes the board cost more because of the board traces and physical port.
I doubt that their hardware does any compositing for the video stream. That would involve reverse engineering how each device driver talks to the board. Not impossible, just unlikely because of the effort. (Also, interacting with the ATI and NVIDIA device drivr would be quite dangerous because each device driver assumes that it is in control of the hardware. The Lucid hardware or software, if it talks to the hardware directly, would make the driver and the board incoherent and lead to system crash)
The smoke and mirrors to this is the requirement for their ASIC. The actual approach is the tried and true solution for graphics hardware: the computation for the color values for each pixel is (mostly) independent of an adjacent pixel; therefore, you just add more hardware to make it faster.
JarredWalton - Sunday, August 24, 2008 - link
You know, doing it in software makes SLI and CF more CPU limited than single GPUs, so unless you're really GPU limited scaling isn't as good as it could be. The whole point of this ASIC seems to be to handle the compositing and assignment of tasks in hardware, thus making it faster and alleviating the CPU of handling such tasks. That's not smoke and mirrors to me... at least, not if it works.It seems like we're still six months or so away from seeing actual hardware in our hands. My impression is also that their goal is to get the hardware to split up generic DX/OGL streams even if it doesn't have a profile, though with a profile it could do a better job. Also, judging by the http://www.dailytech.com/Chipmaker+Hydras+Stunning...">images we've been shown (http://www.pcper.com/article.php?aid=607">more details here, the breaking up of tasks and compositing is FAR more involved than what SLI and CF are doing, and probably makes more sense. (I wasn't at IDF, so I didn't see this in person.)
"Tried and true" has a few synonyms you might want to put in there instead. "Conservative" is one, and so is "stagnation". Just like AMD stagnated with Athlon 64, NVIDIA and ATI seem to be dragging their heels when it comes to true innovation in the GPU industry. GPGPU is the most interesting thing to come out in the past few years, and what do we get? Two proprietary approaches to GPGPU, so that developers need to code for either NVIDIA *or* ATI -- or do twice as much work to support both.
That's a lot like SLI, where NVIDIA wants us to use their GPUs with *their* chipset, and they have been aggressive in preventing other companies from supporting SLI without help from NVIDIA. (ATI is only marginally better - unless something has changed and CF now runs on SLI chipsets without a custom BIOS? But at least ATI will license the tech to Intel.) It would hardly be surprising if a third party were to come out and say "*BEEP* you guys! I'm going to do this in an agnostic fashion and let the users decide."
Whether or not the Lucid Hydra chip works, I can't imagine anyone outside of NVIDIA and ATI employees actually wanting it to fail. You might as well bury your head in the sand and scream loudly that you want all competition and progress to stop. (It won't, of course, but at least if your head is buried you won't be able to tell the difference.)