AMD's Radeon HD 5870: Bringing About the Next Generation Of GPUs
by Ryan Smith on September 23, 2009 9:00 AM EST- Posted in
- GPUs
Cypress: What’s New
With our refresher out of the way, let’s discuss what’s new in Cypress.
Starting at the SPU level, AMD has added a number of new hardware instructions to the SPUs and sped up the execution of other instruction, both in order to improve performance and to meet the requirements of various APIs. Among these changes are that some dot products have been reduced to single-cycle computation when they were previously multi-cycle affairs. DirectX 11 required operations such as bit count, insert, and extract have also been added. Furthermore denormal numbers have received some much-needed attention, and can now be handled at full speed.
Perhaps the most interesting instruction added however is an instruction for Sum of Absolute Differences (SAD). SAD is an instruction of great importance in video encoding and computer vision due to its use in motion estimation, and on the RV770 the lack of a native instruction requires emulating it in no less than 12 instructions. By adding a native SAD instruction, the time to compute a SAD has been reduced to a single clock cycle, and AMD believes that it will result in a significant (>2x) speedup in video encoding.
The clincher however is that SAD not an instruction that’s part of either DirectX 11 or OpenCL, meaning DirectX programs can’t call for it, and from the perspective of OpenCL it’s an extension. However these APIs leave the hardware open to do what it wants to, so AMD’s compiler can still use the instruction, it just has to know where to use it. By identifying the aforementioned long version of a SAD in code it’s fed, the compiler can replace that code with the native SAD, offering the native SAD speedup to any program in spite of the fact that it can’t directly call the SAD. Cool, isn’t it?
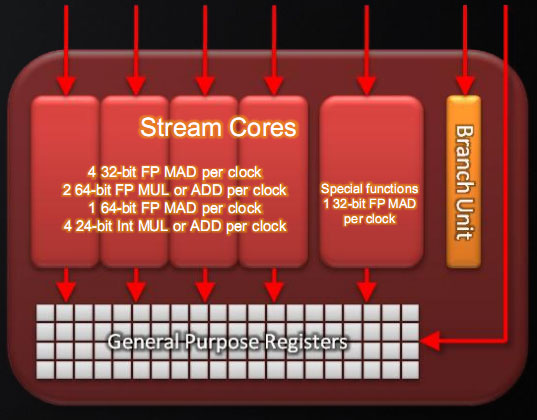
Last, here is a breakdown of what a single Cypress SP can do in a single clock cycle:
- 4 32-bit FP MAD per clock
- 2 64-bit FP MUL or ADD per clock
- 1 64-bit FP MAD per clock
- 4 24-bit Int MUL or ADD per clock
- SFU : 1 32-bit FP MAD per clock
Moving up the hierarchy, the next thing we have is the SIMD. Beyond the improvements in the SPs, the L1 texture cache located here has seen an improvement in speed. It’s now capable of fetching texture data at a blistering 1TB/sec. The actual size of the L1 texture cache has stayed at 16KB. Meanwhile a separate L1 cache has been added to the SIMDs for computational work, this one measuring 8KB. Also improving the computational performance of the SIMDs is the doubling of the local data share attached to each SIMD, which is now 32KB.

At a high level, the RV770 and Cypress SIMDs look very similar
The texture units located here have also been reworked. The first of these changes are that they can now read compressed AA color buffers, to better make use of the bandwidth they have. The second change to the texture units is to improve their interpolation speed by not doing interpolation. Interpolation has been moved to the SPs (this is part of DX11’s new Pull Model) which is much faster than having the texture unit do the job. The result is that a texture unit Cypress has a greater effective fillrate than one under RV770, and this will show up under synthetic tests in particular where the load-it and forget-it nature of the tests left RV770 interpolation bound. AMD’s specifications call for 68 billion bilinear filtered texels per second, a product of the improved texture units and the improved bandwidth to them.
Finally, if we move up another level, here is where we see the cause of the majority of Cypress’s performance advantage over RV770. AMD has doubled the number of SIMDs, moving from 10 to 20. This means twice the number of SPs and twice the number of texture units; in fact just about every statistic that has doubled between RV770 and Cypress is a result of doubling the SIMDs. It’s simple in concept, but as the SIMDs contain the most important units, it’s quite effective in boosting performance.
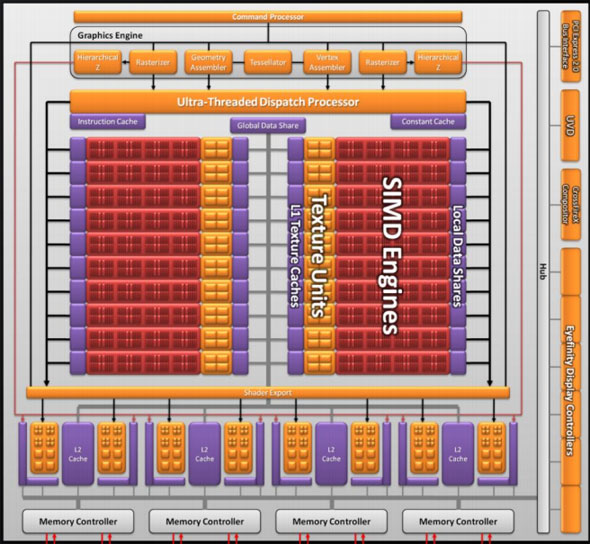
However with twice as many SIMDs, there comes a need to feed these additional SIMDs, and to do something with their products. To achieve this, the 4 L2 caches have been doubled from 64KB to 128KB. These large L2 caches can now feed data to L1 caches at 435GB/sec, up from 384GB/sec in RV770. Along with this the global data share has been quadrupled to 64KB.
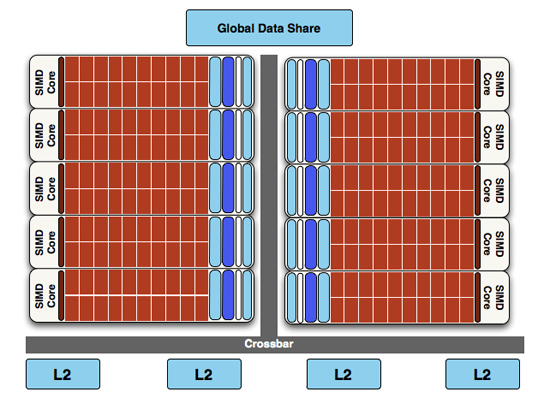
RV770 vs...
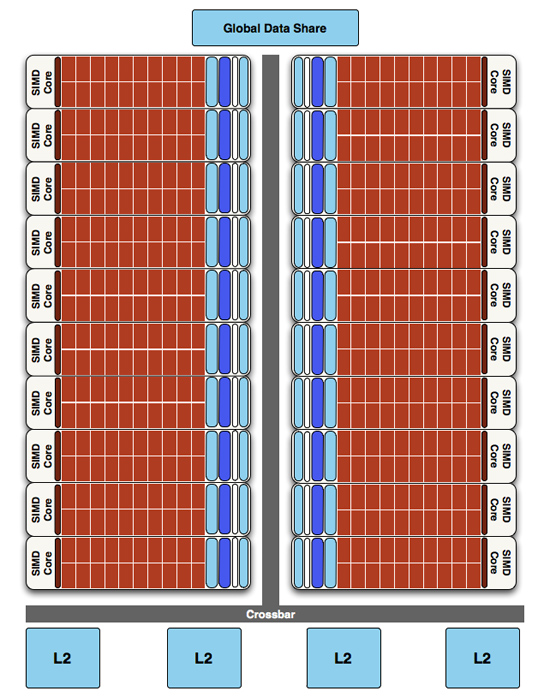
Cypress
Next up, the ROPs have been doubled in order to meet the needs of processing data from all of those SIMDs. This brings Cypress to 32 ROPs. The ROPs themselves have also been slightly enhanced to improve their performance; they can now perform fast color clears, as it turns out some games were doing this hundreds of times between frames. They are also responsible for handling some aspects of AMD’s re-introduced Supersampling Anti-Aliasing mode, which we will get to later.
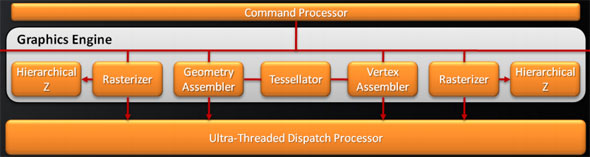
Last, but certainly not least, we have the changes to what AMD calls the “graphics engine”, primarily to bring it into compliance with DX11. RV770’s greatly underutilized tessellator has been upgraded to full DX11 compliance, giving it Hull Shader and Domain Shader capabilities, along with using a newer algorithm to reduce tessellation artifacts. A second rasterizer has also been added, ostensibly to feed the beast that is the 20 SIMDs.








327 Comments
View All Comments
T2k - Thursday, September 24, 2009 - link
Just whatF are you talking about, seriously? Is this some kind of new urban BS again?
Look at other sites, they DID test it with ET:QW:
http://www.techpowerup.com/reviews/ATI/Radeon_HD_5...">http://www.techpowerup.com/reviews/ATI/Radeon_HD_5...
http://www.xbitlabs.com/articles/video/display/rad...">http://www.xbitlabs.com/articles/video/display/rad...
and so on. BTW L4D is a passing fart in the wind while ET:QW is still going strong, stronger than UT3 (unfortunately because UT3 looks 10x better and the old ONS mode was awesome but Epic fucked it in UT3)
Read other reviews before you post:
http://forums.anandtech.com/messageview.aspx?catid...">http://forums.anandtech.com/messageview...amp;thre...
SiliconDoc - Wednesday, September 30, 2009 - link
I see by your review links the 5870 just doesn't do well in ET:QW, everything else is closer to it and it gets beat worse, at 2560 high aa&af GTX295 slams it by 20%, so, of course, it was left out, in order to "pump up the percieved red number".-
It's "not a good appearance".
You'll just have to live with it for now like the rest of us.
number58 - Wednesday, September 23, 2009 - link
Is this card any closer to saturating the pci-express 2.0 x16 slot? That was one of the big arguments in the P55 vs X58 debate. Would there be any loss of performance using these in crossfire on P55 compared to X58?Otherwise, great article. I think I'll be hanging on to my 4890 for a while though.
Kaleid - Wednesday, September 23, 2009 - link
Look here for an answer:http://www.techpowerup.com/reviews/AMD/HD_5870_PCI...">http://www.techpowerup.com/reviews/AMD/HD_5870_PCI...
number58 - Wednesday, September 23, 2009 - link
Thanks. That just about settles it. My next system will be Lynnfield based.Zeratul - Wednesday, September 23, 2009 - link
Please add support for Stereoscopic 3D, ATI. I'm not going back to play games in 2D, though I don't like nvidia's monopoly in that.Arbie - Wednesday, September 23, 2009 - link
Not just a review but an excellent technical discussion. It must have been a lot of work. Thanks for all of that, and do please follow up where you can on people's requests for more info on this very important card.Kudos to ATI/AMD for such an achievement. It looks like Nvidia is in big trouble.
Arbie
SiliconDoc - Wednesday, September 23, 2009 - link
rofl - Nvidia is in big trouble ? LOLHave you looked at the charts on wiki that predicted what this review shows ? Maybe you should take a gander at the Nvidia chart, now, and cry.
--
It is a nice review, although biased red here as usual.
--
I'd like to mention as he fretted about heat because of the 1/2 vent on the back of the card, I didn't notice overt despairing mention of the TWO rectangular exhaust ports on the fan end BLOWING HEAT INTO THE CASE.... which of course is deserved. Nice how that was held back as if overlooked. (Boy what trouble for Nvidia! hahha)
Next we'll be told the red rooster tester put his hand next to the two internal exhaust ports, and "the air felt rather cool" so "rest assured not much heat is being pushed into your case", and "this doesn't matter".
See, the trouble is already in the article, the trouble it took to spin it just so for Ati... lol... it's hilatrious!
ClownPuncher - Wednesday, September 23, 2009 - link
Bizzarro SnakeOil, is that you?SiliconDoc - Wednesday, September 23, 2009 - link
No, this is me, the same me I've always been.Would you like to comment on the two internal exhaust ports of the 5870 that put sweltering heat into your case ?
I guess you tried to ignore that entirely.
You can always insult me again and avoid commenting on the heating exhaust ports ramping up your case temps on the 5870...
That of course would be "the right thing to do".
Perhaps call me crazy, and avoid the topic, right, you're good at that, huh.