AMD's Radeon HD 5870: Bringing About the Next Generation Of GPUs
by Ryan Smith on September 23, 2009 9:00 AM EST- Posted in
- GPUs
Cypress: What’s New
With our refresher out of the way, let’s discuss what’s new in Cypress.
Starting at the SPU level, AMD has added a number of new hardware instructions to the SPUs and sped up the execution of other instruction, both in order to improve performance and to meet the requirements of various APIs. Among these changes are that some dot products have been reduced to single-cycle computation when they were previously multi-cycle affairs. DirectX 11 required operations such as bit count, insert, and extract have also been added. Furthermore denormal numbers have received some much-needed attention, and can now be handled at full speed.
Perhaps the most interesting instruction added however is an instruction for Sum of Absolute Differences (SAD). SAD is an instruction of great importance in video encoding and computer vision due to its use in motion estimation, and on the RV770 the lack of a native instruction requires emulating it in no less than 12 instructions. By adding a native SAD instruction, the time to compute a SAD has been reduced to a single clock cycle, and AMD believes that it will result in a significant (>2x) speedup in video encoding.
The clincher however is that SAD not an instruction that’s part of either DirectX 11 or OpenCL, meaning DirectX programs can’t call for it, and from the perspective of OpenCL it’s an extension. However these APIs leave the hardware open to do what it wants to, so AMD’s compiler can still use the instruction, it just has to know where to use it. By identifying the aforementioned long version of a SAD in code it’s fed, the compiler can replace that code with the native SAD, offering the native SAD speedup to any program in spite of the fact that it can’t directly call the SAD. Cool, isn’t it?
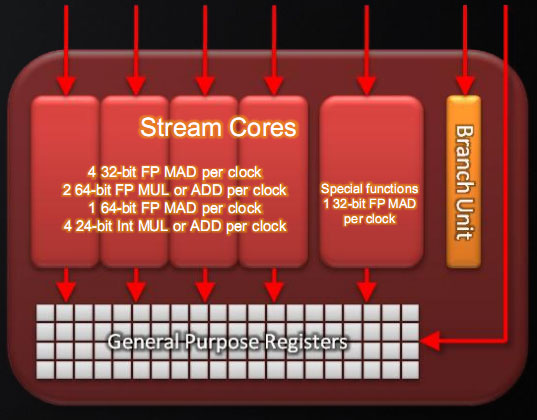
Last, here is a breakdown of what a single Cypress SP can do in a single clock cycle:
- 4 32-bit FP MAD per clock
- 2 64-bit FP MUL or ADD per clock
- 1 64-bit FP MAD per clock
- 4 24-bit Int MUL or ADD per clock
- SFU : 1 32-bit FP MAD per clock
Moving up the hierarchy, the next thing we have is the SIMD. Beyond the improvements in the SPs, the L1 texture cache located here has seen an improvement in speed. It’s now capable of fetching texture data at a blistering 1TB/sec. The actual size of the L1 texture cache has stayed at 16KB. Meanwhile a separate L1 cache has been added to the SIMDs for computational work, this one measuring 8KB. Also improving the computational performance of the SIMDs is the doubling of the local data share attached to each SIMD, which is now 32KB.

At a high level, the RV770 and Cypress SIMDs look very similar
The texture units located here have also been reworked. The first of these changes are that they can now read compressed AA color buffers, to better make use of the bandwidth they have. The second change to the texture units is to improve their interpolation speed by not doing interpolation. Interpolation has been moved to the SPs (this is part of DX11’s new Pull Model) which is much faster than having the texture unit do the job. The result is that a texture unit Cypress has a greater effective fillrate than one under RV770, and this will show up under synthetic tests in particular where the load-it and forget-it nature of the tests left RV770 interpolation bound. AMD’s specifications call for 68 billion bilinear filtered texels per second, a product of the improved texture units and the improved bandwidth to them.
Finally, if we move up another level, here is where we see the cause of the majority of Cypress’s performance advantage over RV770. AMD has doubled the number of SIMDs, moving from 10 to 20. This means twice the number of SPs and twice the number of texture units; in fact just about every statistic that has doubled between RV770 and Cypress is a result of doubling the SIMDs. It’s simple in concept, but as the SIMDs contain the most important units, it’s quite effective in boosting performance.
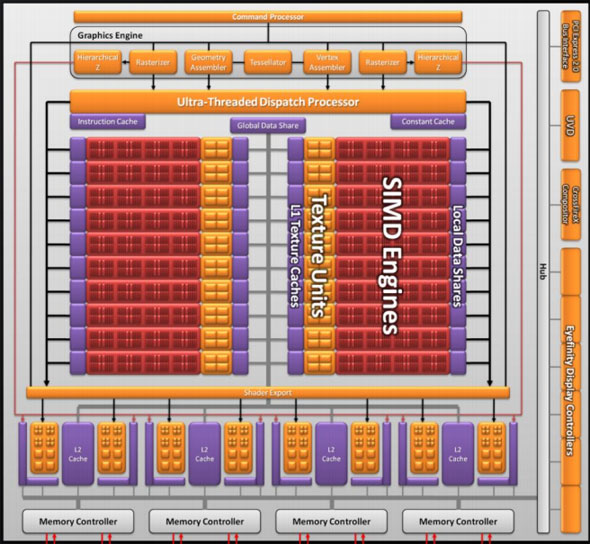
However with twice as many SIMDs, there comes a need to feed these additional SIMDs, and to do something with their products. To achieve this, the 4 L2 caches have been doubled from 64KB to 128KB. These large L2 caches can now feed data to L1 caches at 435GB/sec, up from 384GB/sec in RV770. Along with this the global data share has been quadrupled to 64KB.
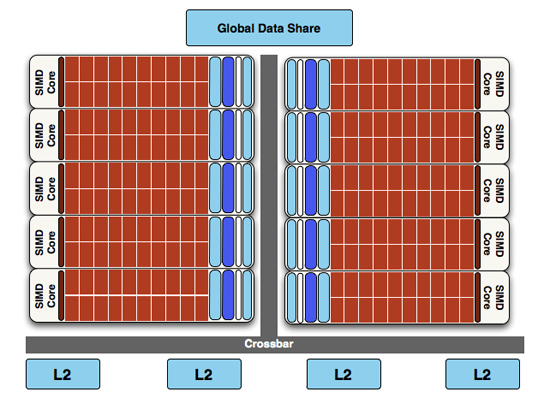
RV770 vs...
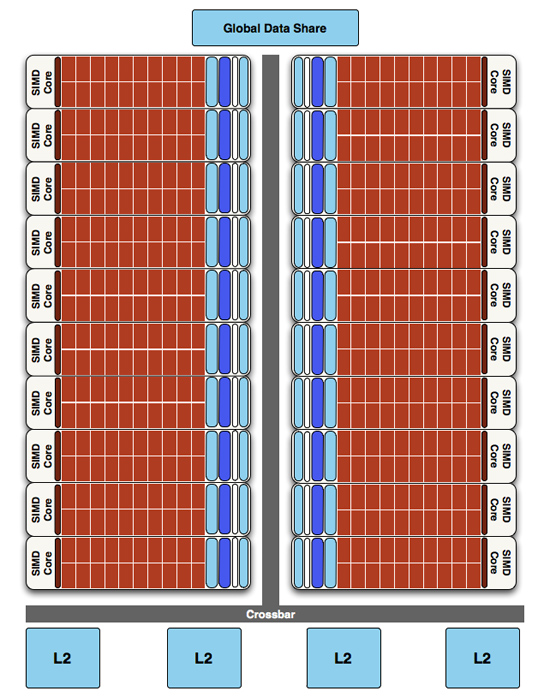
Cypress
Next up, the ROPs have been doubled in order to meet the needs of processing data from all of those SIMDs. This brings Cypress to 32 ROPs. The ROPs themselves have also been slightly enhanced to improve their performance; they can now perform fast color clears, as it turns out some games were doing this hundreds of times between frames. They are also responsible for handling some aspects of AMD’s re-introduced Supersampling Anti-Aliasing mode, which we will get to later.
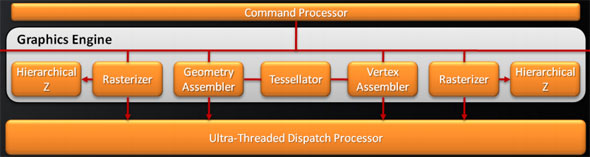
Last, but certainly not least, we have the changes to what AMD calls the “graphics engine”, primarily to bring it into compliance with DX11. RV770’s greatly underutilized tessellator has been upgraded to full DX11 compliance, giving it Hull Shader and Domain Shader capabilities, along with using a newer algorithm to reduce tessellation artifacts. A second rasterizer has also been added, ostensibly to feed the beast that is the 20 SIMDs.








327 Comments
View All Comments
RubberJohnny - Thursday, September 24, 2009 - link
Well silicondoc you sure have some hatred for ATI/love for nvidia.It's almost as if you work for the green team...
You seem to have all this time on your hands to go around the net looking for links to spread FUD...sitting on new egg watching these cards come in and out of stock like you have a vested interest in seeing ATI fail...unlike any sane person it appears you want nvidia to have a monopoly on the industry?
Maybe you are privy to some inside info over at nvidia and know they have nothing to counter the 5870 with?
Maybe the cash they paid you to spin these BS comments would have been better spent on R&D?
SiliconDoc - Thursday, September 24, 2009 - link
That's a nice personal, grating, insulting ripppp, it's almost funny, too.---
The real problems remain.
I bring up this stuff because of course, no one else will, it is almost forbidden. Telling the truth shouldn't be that hard, and calling it fairly and honestly should not be such a burden.
I will gladly take correction when one of you noticing insulters has any to offer. Of course, that never comes.
Break some new ground, won't you ?
I don't think you will, nor do I think anyone else will - once again, that simply confirms my factual points.
I guess I'll give you a point for complaining about delivery, if that's what you were doing, but frankly, there are a lot of complainers here no different - let's take for instance the ATI Radeon HD 4890 vs. NVIDIA GeForce GTX 275 article here.
http://www.anandtech.com/video/showdoc.aspx?i=3539">http://www.anandtech.com/video/showdoc.aspx?i=3539
Boy, the red fans went into rip mode, and Anand came in and changed the articles (Derek's) words and hence "result", from GTX275 wins to ATI4890 wins.
--
No, it's not just me, it's just the bias here consistently leans to ati, and wether it's rooting for the underdog that causes it, or the brooding undercurrent hatred that surfaces for "the bigshot" "greedy" "ripoff artist" "nvidia overchargers" "industry controlling and bribing" "profit demon" Nvidia, who knows...
I'm just not afraid to point it out, since it's so sickening, yes, probably just to me, "I'm sure".
How about this glaring one I have never pointed out even to this day, but will now:
ATI is ALWAYS listed first, or "on top" - and of course, NVIDIA, second, and it is no doubt, in the "reviewer's minds" because of "the alphabet", and "here we go in alphabetical order".
A very, very convenient excuse, that quite easily causes a perception bias, that is quite marked for the readers.
But, that's ok.
---
So, you want to tell me why I shouldn't laugh out loud when ATI uses NVIDIA cards to develope their "PhysX" competition Bullet ?
ROFLMAO
I have heard 100 times here (from guess whom) that the ati has the wanted "new technology", so will that same refrain come when NVIDIA introduces their never before done MIMD capable cores in a few months ? LOL
I can hardly wait to see the "new technology" wannabes proclaiming their switched fealty.
Gee sorry for noticing such things, I guess I should be a mind numbed zombie babbling along with the PC required fanning for ati ?
silverblue - Thursday, September 24, 2009 - link
No; if he did work for nVidia, he'd be far better informed and far less prone to using the phrase "red rooster" every five seconds.crackshot91 - Wednesday, September 23, 2009 - link
Any possibility of benchmarks with a core 2 duo?I wanna know if it will be necessary to upgrade to an i5 or i7 (All new mobo) to see big performance gains over my 8800GT. Will a C2D E6750 @ 3.2GHz bottleneck it?
Ryan Smith - Wednesday, September 23, 2009 - link
Our recent Core i7 860 article should do an adequate job of answering that question. Several of the benchmarks were taken right out of this article.therealnickdanger - Wednesday, September 23, 2009 - link
You dedicated a full page to the flawless performance of its A/V output, but didn't mention it in the "features" part of the conclusion. It's a very powerful feature, IMO. Granted, this card may be a tad too hot and loud to find a home in a lot of HTPCs, but it's still an awesome feature and you should probably append your conclusion... just a suggestion though.Ultimately, I have to admit to being a little disappointed by the performance of this card. All the Eyefinity hype and playable framerates at massive 7000x3000 resolutions led me to believe that this single card would scale down and simply dominate everything at the 30" level and below. It just seems logical, so I was taken aback when it was beat by, well, anything else. I expected the 5870 and 5870CF to be at the top of every chart. Oh well.
Awesome article though! I'm sure there's a 5850 in my future!
MrMom - Wednesday, September 23, 2009 - link
Does anyone have a good explanation why the massive HD5870 is still slower/@par with the GTX295?Thanks
SiliconDoc - Thursday, September 24, 2009 - link
Yes, because the ati core "really sucks". It needs DDR5, and much higher MHZ to compete with Nvidia, and their what, over 1 year old core. LOL Even their own 4870x2.Or the 3 year old G92 vs the ddr3 "4850" the "topcore" before yesterday. (the ati topcore minus the well done 3m mhz+ REBRAND ring around the 4890)
That's the sad, actual truth. That's the truth many cannot bear to bring themselves to realize, and it's going to get WORSE for them very soon, with nvidia's next release, with ddr5, a 512 bit bus, and the NEW TECHNOLOGY BY NVIDIA THAT ATI DOES NOT HAVE MIMD capable cores.
Oh, I can hardly wait, but you bet I'm going to wait, you can count on that 100%.
Spoelie - Thursday, September 24, 2009 - link
because those are 2 480mm² dies, while this is only 1 360mm² die?Griswold - Wednesday, September 23, 2009 - link
Its one GPU instead of two, maybe?