AMD's Radeon HD 5870: Bringing About the Next Generation Of GPUs
by Ryan Smith on September 23, 2009 9:00 AM EST- Posted in
- GPUs
Cypress: What’s New
With our refresher out of the way, let’s discuss what’s new in Cypress.
Starting at the SPU level, AMD has added a number of new hardware instructions to the SPUs and sped up the execution of other instruction, both in order to improve performance and to meet the requirements of various APIs. Among these changes are that some dot products have been reduced to single-cycle computation when they were previously multi-cycle affairs. DirectX 11 required operations such as bit count, insert, and extract have also been added. Furthermore denormal numbers have received some much-needed attention, and can now be handled at full speed.
Perhaps the most interesting instruction added however is an instruction for Sum of Absolute Differences (SAD). SAD is an instruction of great importance in video encoding and computer vision due to its use in motion estimation, and on the RV770 the lack of a native instruction requires emulating it in no less than 12 instructions. By adding a native SAD instruction, the time to compute a SAD has been reduced to a single clock cycle, and AMD believes that it will result in a significant (>2x) speedup in video encoding.
The clincher however is that SAD not an instruction that’s part of either DirectX 11 or OpenCL, meaning DirectX programs can’t call for it, and from the perspective of OpenCL it’s an extension. However these APIs leave the hardware open to do what it wants to, so AMD’s compiler can still use the instruction, it just has to know where to use it. By identifying the aforementioned long version of a SAD in code it’s fed, the compiler can replace that code with the native SAD, offering the native SAD speedup to any program in spite of the fact that it can’t directly call the SAD. Cool, isn’t it?
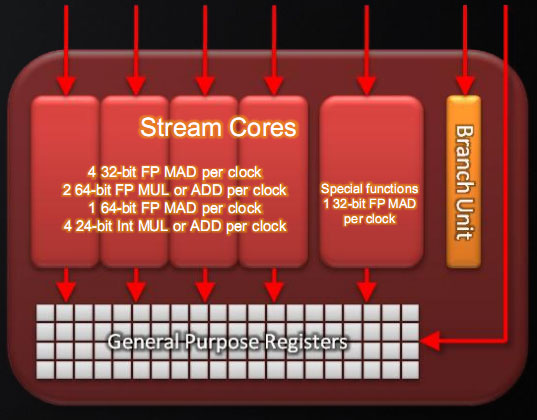
Last, here is a breakdown of what a single Cypress SP can do in a single clock cycle:
- 4 32-bit FP MAD per clock
- 2 64-bit FP MUL or ADD per clock
- 1 64-bit FP MAD per clock
- 4 24-bit Int MUL or ADD per clock
- SFU : 1 32-bit FP MAD per clock
Moving up the hierarchy, the next thing we have is the SIMD. Beyond the improvements in the SPs, the L1 texture cache located here has seen an improvement in speed. It’s now capable of fetching texture data at a blistering 1TB/sec. The actual size of the L1 texture cache has stayed at 16KB. Meanwhile a separate L1 cache has been added to the SIMDs for computational work, this one measuring 8KB. Also improving the computational performance of the SIMDs is the doubling of the local data share attached to each SIMD, which is now 32KB.

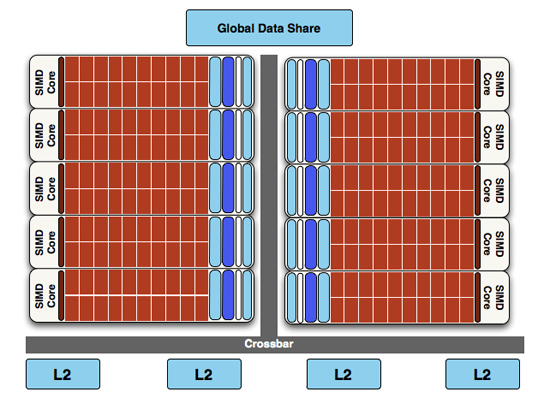
At a high level, the RV770 and Cypress SIMDs look very similar
The texture units located here have also been reworked. The first of these changes are that they can now read compressed AA color buffers, to better make use of the bandwidth they have. The second change to the texture units is to improve their interpolation speed by not doing interpolation. Interpolation has been moved to the SPs (this is part of DX11’s new Pull Model) which is much faster than having the texture unit do the job. The result is that a texture unit Cypress has a greater effective fillrate than one under RV770, and this will show up under synthetic tests in particular where the load-it and forget-it nature of the tests left RV770 interpolation bound. AMD’s specifications call for 68 billion bilinear filtered texels per second, a product of the improved texture units and the improved bandwidth to them.
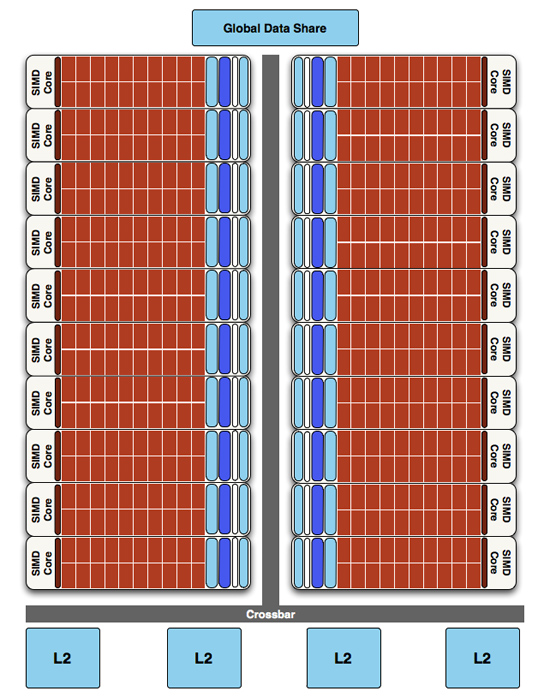
Finally, if we move up another level, here is where we see the cause of the majority of Cypress’s performance advantage over RV770. AMD has doubled the number of SIMDs, moving from 10 to 20. This means twice the number of SPs and twice the number of texture units; in fact just about every statistic that has doubled between RV770 and Cypress is a result of doubling the SIMDs. It’s simple in concept, but as the SIMDs contain the most important units, it’s quite effective in boosting performance.
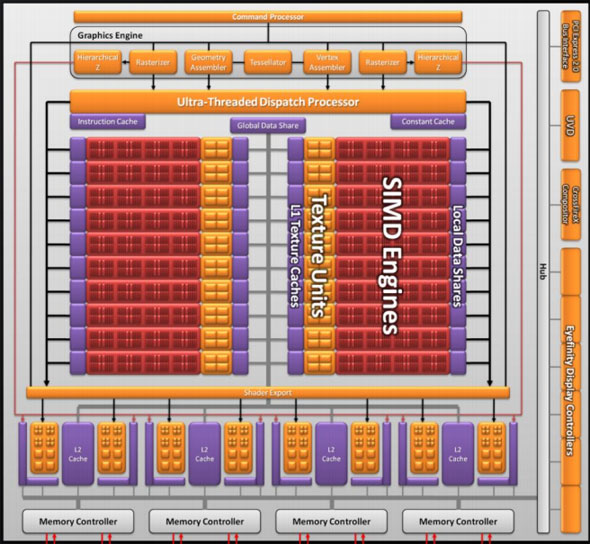
However with twice as many SIMDs, there comes a need to feed these additional SIMDs, and to do something with their products. To achieve this, the 4 L2 caches have been doubled from 64KB to 128KB. These large L2 caches can now feed data to L1 caches at 435GB/sec, up from 384GB/sec in RV770. Along with this the global data share has been quadrupled to 64KB.
RV770 vs...
Cypress
Next up, the ROPs have been doubled in order to meet the needs of processing data from all of those SIMDs. This brings Cypress to 32 ROPs. The ROPs themselves have also been slightly enhanced to improve their performance; they can now perform fast color clears, as it turns out some games were doing this hundreds of times between frames. They are also responsible for handling some aspects of AMD’s re-introduced Supersampling Anti-Aliasing mode, which we will get to later.
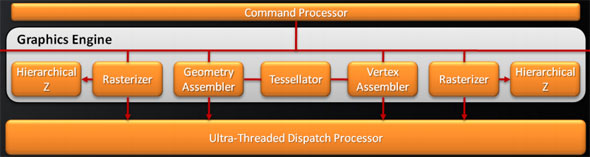
Last, but certainly not least, we have the changes to what AMD calls the “graphics engine”, primarily to bring it into compliance with DX11. RV770’s greatly underutilized tessellator has been upgraded to full DX11 compliance, giving it Hull Shader and Domain Shader capabilities, along with using a newer algorithm to reduce tessellation artifacts. A second rasterizer has also been added, ostensibly to feed the beast that is the 20 SIMDs.








327 Comments
View All Comments
Ryan Smith - Wednesday, September 23, 2009 - link
We do have Cyberlink's software, but as it uses different code paths, the results are near-useless for a hardware review. Any differences could be the result of hardware differences, or it could be that one of the code paths is better optimized. We would never be able to tell.Our focus will always be on benchmarking the same software on all hardware products. This is why we bent over backwards to get something that can use DirectCompute, as it's a standard API that removes code paths/optimizations from the equation (in this case we didn't do much better since it was a NVIDIA tech demo, but it's still an improvement).
DukeN - Wednesday, September 23, 2009 - link
I have one of these and I know it outperforms the GTX 280 but not sure what it'd be like against one of these puppies.dagamer34 - Wednesday, September 23, 2009 - link
I need my bitstream Dolby Digital TrueHD/DTS HD Master Audio bistreaming codecs!!! :)ew915 - Wednesday, September 23, 2009 - link
I don't see this beating the GT300 as for so it should beat the GTX295 by a great margin.tamalero - Wednesday, September 23, 2009 - link
dood, you forgot the 295 is a DUAL CHIP?SiliconDoc - Wednesday, September 23, 2009 - link
roflmao - Gee no more screaming the 4850x2 and the 4870x2 are best without pointing out the two gpu's needed to get there.--
Nonetheless, this 5870 is EPIC FAIL, no matter what - as we see the disappointing numbers - we all see them, and it's not good.
---
Problem is, Nvidia has the MIMD multiple instructions breakthrough technology never used before that according to reports is an AWESOME advantage, lus they are moving to DDR5 with a 512 bit bus !
--
So what is in the works is an absolute WHOMPING coming down on ati that BIG GREEN NVIDIA is going to deliver, and the poor numbers here from what was hoped for and hyped over (although even PREDICTED by the red fan Derek himself in one portion of one sorrowful and despressed sentence on this site) are just one step closer to that nail in the coffin...
--
Yes I sure hope ati has something major up it's sleeve, like 512 bit mem bus increased card coming, the 5870Xmem ...
I find the speculation that ATI "mispredicted" the bandwidth needs to be utter non-sense. They are 2-3 billion in the hole from the last few years with "all these great cards" they still lose $ on every single sale, so they either cannot go higher bit width, or they don't want to, or they are hiding it for the next "strike at NVidia" release.
erple2 - Friday, September 25, 2009 - link
So you're comparing this product with a not yet release product and saying that the not yet released product is going to trounce it, without any facts to back it up? Do you have the hardware? If not, then you're simply ranting.Will the GT300 beat out the 5870? I dunno, probably. If it didn't, that would imply that the move from GT200 to GT300 was a major disappointment for NVidia.
I think that EPIC FAIL is completely ludicrous. I can see "epic fail" applied to the Geforce FX series when it came out. I can also see "epic fail" for the Radeon MAXX back in the day. But I don't see the 5870 as "epic fail". If you look at the card relative to the 4870 (the card it replaces), it's quite good - solid 30% increase. That's what I would expect from a generation improvement (that's what the gt200's did over the 9800's, and what the 8800 did over the 7900, etc).
BTW, I'm seeing the 5870 as pretty good - it beats out all single card NVidia by a reasonable and measureable amount. Sounds like ATI has done well. Or are you considering anything less than 2x the performance of the NVidia cards "epic fail"? In that case, you may be disappointed with the GT300, as well. In fact, I'll say that the GT300 is a total fail right now. I mean jeez! It scores ZERO FPS in every benchmark! That's super-epic fail. And I have the numbers to back that statement up.
Since you are making claims about the epic fail nature of the 5870 based on yet to be released hardware, I can certainly play the same game, and epic fail anything you say based on those speculative musings.
SiliconDoc - Monday, September 28, 2009 - link
Well the GT200 was 60.96% increase average. AT says so.http://www.anandtech.com/video/showdoc.aspx?i=3334...">http://www.anandtech.com/video/showdoc.aspx?i=3334...
So, I guess ati lost this round terribly, as NVidia's last just beat them by more than double your 30%.
Great, EPIC FAIL is correct, I was right, and well...
Finally - Wednesday, September 23, 2009 - link
Team Green foames out of their mouthes. It's funny to watch.SiliconDoc - Wednesday, September 23, 2009 - link
Glad you are having fun.Just let me know when you disagree, and why. I'm certain your fun will be "gone then", since reality will finally take hold, and instead of you seeing foam, I'll be seeing drool.