NVIDIA's Fermi: Architected for Tesla, 3 Billion Transistors in 2010
by Anand Lal Shimpi on September 30, 2009 12:00 AM EST- Posted in
- GPUs
ECC Support
AMD's Radeon HD 5870 can detect errors on the memory bus, but it can't correct them. The register file, L1 cache, L2 cache and DRAM all have full ECC support in Fermi. This is one of those Tesla-specific features.
Many Tesla customers won't even talk to NVIDIA about moving their algorithms to GPUs unless NVIDIA can deliver ECC support. The scale of their installations is so large that ECC is absolutely necessary (or at least perceived to be).
Unified 64-bit Memory Addressing
In previous architectures there was a different load instruction depending on the type of memory: local (per thread), shared (per group of threads) or global (per kernel). This created issues with pointers and generally made a mess that programmers had to clean up.
Fermi unifies the address space so that there's only one instruction and the address of the memory is what determines where it's stored. The lowest bits are for local memory, the next set is for shared and then the remainder of the address space is global.
The unified address space is apparently necessary to enable C++ support for NVIDIA GPUs, which Fermi is designed to do.
The other big change to memory addressability is in the size of the address space. G80 and GT200 had a 32-bit address space, but next year NVIDIA expects to see Tesla boards with over 4GB of GDDR5 on board. Fermi now supports 64-bit addresses but the chip can physically address 40-bits of memory, or 1TB. That should be enough for now.
Both the unified address space and 64-bit addressing are almost exclusively for the compute space at this point. Consumer graphics cards won't need more than 4GB of memory for at least another couple of years. These changes were painful for NVIDIA to implement, and ultimately contributed to Fermi's delay, but necessary in NVIDIA's eyes.
New ISA Changes Enable DX11, OpenCL and C++, Visual Studio Support
Now this is cool. NVIDIA is announcing Nexus (no, not the thing from Star Trek Generations) a visual studio plugin that enables hardware debugging for CUDA code in visual studio. You can treat the GPU like a CPU, step into functions, look at the state of the GPU all in visual studio with Nexus. This is a huge step forward for CUDA developers.
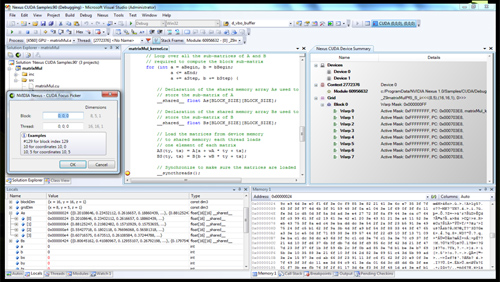
Nexus running in Visual Studio on a CUDA GPU
Simply enabling DX11 support is a big enough change for a GPU - AMD had to go through that with RV870. Fermi implements a wide set of changes to its ISA, primarily designed at enabling C++ support. Virtual functions, new/delete, try/catch are all parts of C++ and enabled on Fermi.








415 Comments
View All Comments
Griswold - Wednesday, September 30, 2009 - link
Well, you have to consider that nvidia is getting between a rock and a hard place. The PC gaming market is shrinking. Theres not much point in making desktop chipsets anymore... they have to shift focus (and I'm sure they will focus) on new things like GPGPU. I wont be surprised if GT300 wont be a the super awesome gamer GPU of choice so many people expect it to be. And perhaps, the one after GT300 will be even less impressive for gaming, regardless of what they just said about making humongous chips for the high-end segment.SiliconDoc - Wednesday, September 30, 2009 - link
Gee nvidia is between a rock and a hard place, since they have an OUT, and ATI DOES NOT.lol
That was a GREAT JOB focusing on the wrong player who is between a rock and a hard place, and that player would be RED ROOSTER ATI !
--
no chipsets
no chance at TESLA sales in the billions to coleges and government and schools and research centers all ove the world....
--
buh bye ATI ! < what you should have actually "speculated"
...
But then, we know who you are and what you're about -
TELLING THE EXACT OPPSITE OF THE TRUTH, ALL FOR YOUR RED GOD, ATI !
--
silverblue - Thursday, October 1, 2009 - link
When nVidia actually sends out Fermi samples for previews/reviews, only then will you know how good it is. We all want to see it because we want competition and lower prices (and maybe some of us will buy one or more, as well!).Until then, keep your fanboy comments to yourself.
SiliconDoc - Thursday, October 1, 2009 - link
No silverblue, that is in fact your problem, not mine, as you won't know anything, till you're shown a lie or otherwise, and it's shoved into your tiny processor for your personal acceptance.The fact remains, red fanboy raver Griswold blew it, and I pointed out exactly WHY.
The fact that you cry about it, because you group stupid dummies keep blowing nearly every statement you make, sure isn't my fault.
silverblue - Thursday, October 1, 2009 - link
I wonder if you do actually read posts before you reply to them.SiliconDoc - Thursday, October 1, 2009 - link
Take your own advice, you pathetic hypocrit.ClownPuncher - Thursday, October 1, 2009 - link
Its actually "hypocrite".SiliconDoc - Friday, October 2, 2009 - link
It's "it's", you pathetic hypocrit.silverblue - Friday, October 2, 2009 - link
It's "hypocrite", you pathetic hypocrite.chizow - Wednesday, September 30, 2009 - link
Nvidia is simply hedging their bets and expanding their horizons. They've still managed to offer the fastest GPUs per product cycle/generation and they're clearly far more advanced than AMD when it comes to GPGPU in both theory and practice.Jensen's keynote tipped his hat numerous times to Nvidia's roots as a GPU company that designed chips to run 3D video games, but the focus of his presentation was clearly to sell it as more than that, as a cGPU capable of incredible computational ability.