NVIDIA's Fermi: Architected for Tesla, 3 Billion Transistors in 2010
by Anand Lal Shimpi on September 30, 2009 12:00 AM EST- Posted in
- GPUs
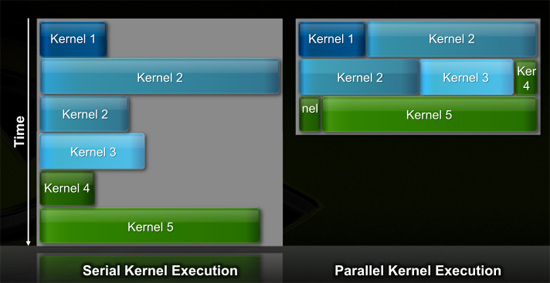
Efficiency Gets Another Boon: Parallel Kernel Support
In GPU programming, a kernel is the function or small program running across the GPU hardware. Kernels are parallel in nature and perform the same task(s) on a very large dataset.
Typically, companies like NVIDIA don't disclose their hardware limitations until a developer bumps into one of them. In GT200/G80, the entire chip could only be working on one kernel at a time.
When dealing with graphics this isn't usually a problem. There are millions of pixels to render. The problem is wider than the machine. But as you start to do more general purpose computing, not all kernels are going to be wide enough to fill the entire machine. If a single kernel couldn't fill every SM with threads/instructions, then those SMs just went idle. That's bad.
GT200 (left) vs. Fermi (right)
Fermi, once again, fixes this. Fermi's global dispatch logic can now issue multiple kernels in parallel to the entire system. At more than twice the size of GT200, the likelihood of idle SMs went up tremendously. NVIDIA needs to be able to dispatch multiple kernels in parallel to keep Fermi fed.
Application switch time (moving between GPU and CUDA mode) is also much faster on Fermi. NVIDIA says the transition is now 10x faster than GT200, and fast enough to be performed multiple times within a single frame. This is very important for implementing more elaborate GPU accelerated physics (or PhysX, great ;)…).
The connections to the outside world have also been improved. Fermi now supports parallel transfers to/from the CPU. Previously CPU->GPU and GPU->CPU transfers had to happen serially.








415 Comments
View All Comments
silverblue - Thursday, October 1, 2009 - link
Anand's entitled to make mistakes. You do nothing else.SiliconDoc - Thursday, October 1, 2009 - link
Oh golly, another lie.First you admit I'm correct, FINALLY, then you claim only mistakes from me.
You're a liar again.
However, I congratulate you, for FINALLY having the half baked dishonesty under enough control that you offer an excuse for Anand.
That certainly is progress.
silverblue - Friday, October 2, 2009 - link
And you conveniently forget the title of this article which clearly states 2010.johnsonx - Wednesday, September 30, 2009 - link
I think there might be something wrong with SiliconDoc. Something wrong in the head.SiliconDoc - Thursday, October 1, 2009 - link
I think that pat fancy can now fairly be declared the quacking idiot group collective's complete defense.Congratulations, you're all such a pile of ignorant sheep, you'll swather together the same old feckless riddle for eachothers emotional comfort, and so far to here, nearly only monkeypaw tried to address the launch lie pointed out.
I suppose a general rule, you love your mass hysterical delusionary appeasement, in leiu of an actual admittance, understanding, or mere rebuttal to the author's false launch accusation in the article, the warped and biased comparisons pointed out, and the calculations required to reveal the various cover-ups I already commented on.
Good for you people, when the exposure of bias and lies is too great to even attempt to negate, it's great to be a swaddling jerkoff in union.
I certainly don't have to wonder anymore.
Griswold - Wednesday, September 30, 2009 - link
So, you're the new village fool?Finally - Thursday, October 1, 2009 - link
Make that "Global Village Fool 2.0"He is an advanced version, y'know?
SiliconDoc - Wednesday, September 30, 2009 - link
Nvidia LAUNCHED TODAY... se page two by your insane master Anand.--
YOU'VE all got the same disease.
MonkeyPaw - Wednesday, September 30, 2009 - link
Is sanity now considered to be a disease? We're not the one's visiting a website in which we so aggressively scream "bias" on (apparently) every GPU article. If you think Anand's work is so offensive and wrong, then why do you keep coming back for more?Anyway, I just don't see where you get this "bias" talk. For crying out loud, you can't make many assumptions about the product's performance when you don't even know the clock speeds. You can guess till you're blue in the face, but that still leaves you with no FACTS. Also keep in mind that GT300 will have ECC enabled (at least in Tesla), which has been known to affect latency and clock speeds in other realms. I'm not 100% sure how the ECC spec works in GDDR5, but usually ECC comes at a cost.
As for "paper launch," ultimately semantics don't matter. However, a paper launch is generally defined as a product announcement that you cannot buy yet. It's frequently used as a business tactic to keep people from buying your competitor's products. If the card is officially announced (and it hasn't), but no product is available, then by my definition, it is a paper launch. However, everyone has their own definition of the term. This article I see more as a technology preview, though nVidia's intent is still probably to keep people from buying an RV870 right now. That's where the line blurs.
SiliconDoc - Thursday, October 1, 2009 - link
A launch date is the date the company claims PRODUCT WILL BE AVAILABLE IN RETAIL CHANNELS.No "semantics" you whine about or cocka doodle do up will change that.
A LAUNCH date officially as has been for YEARS sonny paw, is when the corp says "YOU CAN BUY THIS" as a private end consumer.
---
Anything ELSE is a showcase, an announcement, a preview of upcoming tech, a marketing plan, ETC.
---
YOU LTING ABOUT THE VERY ABSOLUTE FACTS THAT FOR YEARS HAVE APPLIED PERIOD IS JUST ANOTHER RED ROOSTER NOTCH ACQUIRED.